
EECS498 Computer Vision with Justin
Lecture 1 - Introduction
How many images uploaded to Instagram daily?
1.3 billion.
What are 3 factors that contributed to the rise of computer vision in the past decade?
Better data + storage.
Better processing power.
Lots of data.
Readings
Python Tutorial
Have a look if you’re confused by some dum shit numpy decides to do.*
*Actually, you’re dum, bc it’s a computer and you need to know how to use it; but insofar as the customer is never wrong, you’re not dum.
GBC Section 1.0 Introduction
I didn’t actually have to read this, but I read it anyway because I’m a chump who can’t read instructions properly.
What is the multiple step interpretation of why deep neural networks are more effective than simply logistic regression?
Like a computer program does some processing and gets some new variables, so each layer is a new collection of relevant variables needed in the next step. Logistic regression is directly input → output with little inbetween.
Why use deep networks instead of logistic regression of features?
Logistic regression may not identify features in more complex tasks where features are very abstract, like pixel values in an image, rather than more meaningful features such as age, weight, height, etc..
What are 2 ways of computing depth of a deep network?
- Make a computational graph, where each ‘layer’ is a new computation
- Make a conceptual graph (probabilistic modelling graph)
These two overlap, but (1) counts the number of computations whereas (2) counts the number of conceptual investigations/computations.
Overall, depth is not straight forward, and is more of a concept that a rigorous definition.
What is a deep network?
One that has considerably more computations that traditional machine learning algorithms.
GBC Section 1.2 Historical Trends In Deep Learning
This I did have to read…
How does the brain suggest that general artificial intelligence is possible?
It is a collection of communicating nodes, with corresponding algorithms.
If we can completely map the relationship between neurons in the brain/body to neural networks in computers then we can simulate the intelligence generated by the brain.
How might neural networks influence neuroscience?
If we learn efficient algorithms for making efficient neural networks, we may find more accurate descriptions of relationships between neurons in the brain.
What is a linear model? Me
f(x,w) = x1w1 + … + xnwn
What was the initial backlash against linear models?
They couldn't create a function for XOR.
What is distributed representation?
Classes of properties of an input are found independently of each other.
So if we have 3 colors, RGB, and 3 objects, car, horse, plane, we could have 9 possible combinations, red car, green plane, etc.. but instead of classifying between 9 possibilites, first you see what the object is, a car, horse, or plane, and then see which color it is.
This is good because you can use many different color planes to train the “is it a plane?” layer, instead of only using green planes so as to indentify green planes better, and conversely we can use different objects of the same color to train the colors.
What has likely caused the increase in neural networks from 2006 to 2023 (now)?
- Better computers
- More Data
- Better software architectures
- Better neural network algorithms
What is a rule of thumb for the number of examples required for a neural network to learn a specific category of input?
5000 examples per category. 10 million total examples to beat human performance. (~2000 classes)
What is a top 5 error rate?
The rate at which the correct class does not come up in the neural networks top 5 guesses of the correct class.
What are neural Turing machines? (INTERESTING)
A machine that has states and symbols and randomly reads from and writes to memory, and is tested against it’s ability to complete a task, such as sorting a list.
GBC Section 6.6 Historical Notes
What are 2 neural network changes that increased accuracy since the 1980s?
- Cross entropy loss.
- ReLU activation functions.
Why is ReLU lowkey OP?
been under-repped, sad days. Turns out it’s hella dope.
What are 3 features of how biological neurons work in relation to the ReLU activation function?
- Neurons can be in states of total disactivation, like 0 in ReLU and unlike 0.01 in sigmoid.
- For inputs that are large enough, the output is proportional to the input.
- Most inputs don’t pass/activate the neuron; it’s a sparse network.
Lecture 2 - Image Classification
What are 7 (image-related) challenges in making effective CV models?
- Lighting conditions
- Background noise
- Occlusion (things in the way)
- visual perspective variation
- intraclass variation (5 different cats in the same photo)
- fine-grained classes (not cat, but Siamese cat)
- Deformation:

What are 3 use cases for image classification?
- Medical Imaging
- Galaxy identification
- Whale recognition
Countless others. I know a company X (through a guy) that detects weeds along railroads, which may compromise the safety of the track over time.
What are 2 initial, hard coded, ideas to CV? Why do they suck?
- Find edges
- Find corners
Then relate them someeeehow 🤷.
They suck because:
- Relegated to specific use cases, like pictures of cats
- A lot of mental effort for just 1 use case
- Need to account for a lot of potential variations, i.e. the 7 challenges above.
What are 3 standard datasets for CV?
- MNIST - toy set, used for a proof of concept
- CIFAR10 or CIFAR100 - bigger, better set, with more complicated images, still fairly small though
- Imagenet - Huge dataset, pretty standard for suggesting that a network architecture works well.
What is another huge dataset?
MIT Places, which has more images than imagenet of places, like fields, deserts, etc..
What is low shot classification? What is a dataset often used in such training?
Low shot classification requires few examples to get high accuracy on testing data.
Omniglot is the name of the dataset.
What is nearest neighbour classification?
In the context of CV, you have an image, and you want to compare how ‘similar’ that image is to any other image.
So when testing, you look at the test image, compare it to every image in the training set and get the difference using distance metrics.
Then you get the k nearest images (those with the lowest distance), and the most common label among them is your classification choice.
There is no training.
What are some distance metrics for nearest neighbour?
L1 - Manhattan distance.
Let be our vectors, or our K-dimensional tensors, stretched out into a vectors, both of length .
Our L1 distance is
L2 - Euclidean Distance is
And then, whatever you want. Vector and matrix norms? GO FOR IT.
Get creative broski.
What are decision boundaries with nearest neighbour classification?
Better explained with an image (the black line):
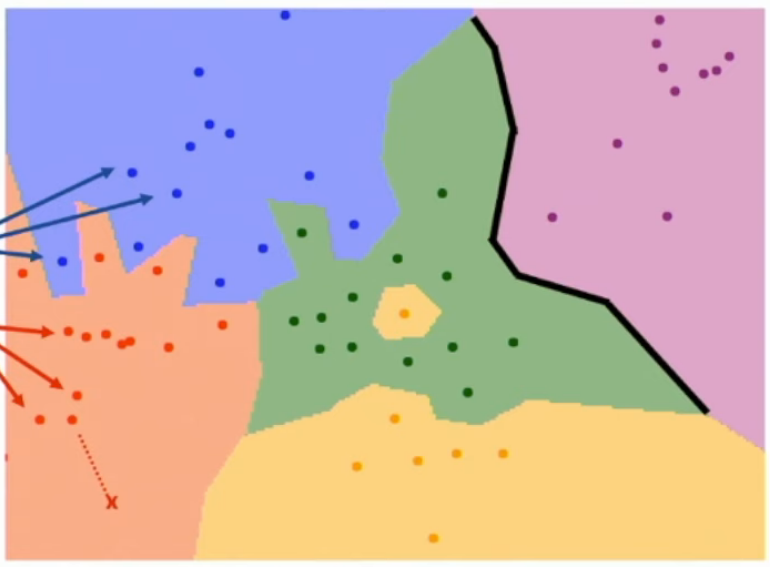
They’re the vector functions (for Nd space), that separate two or more classes.
What are some reasons that nearest neighbour sucks?
- Training is fast, testing is slow. This is almost* the opposite of what we want.
- Distance metrics are kind of arbitrary and choosing a good one might be what makes KNNs work.
Note KNNs work well in some cases, but I don’t know the specifics of why.
Try reading Delvin et al. 2015 for image captioning using KNNs.
*What we want is fast both, but usually we get slow training, which is fine, so long as testing is fast, since that’s where the real world use is.
What is the curse of dimensionality?
Roughly exhausting most points on a line, to get an approximation to it, is fairly easy.
The problem is squared if you approximated a plane.
Then cubed if you approximated a volume.
As dimensionality goes up*, it becomes basically impossible to use enough data points to ‘exhaust’ that space.
*i.e. 256x256x3 pixels in an image are the input and hence the dimension
Readings
CS231n Image classification
What is k-fold validation/cross-validation?
Split training data into k subsets, use one subset for validation and the rest for training, see which hyper-parameters work best, repeat for all k possibilities and choose the best performing hyper-params over all of them.
Lecture 3 - Linear Classifiers
What is a linear classifier?
Stetch your image into a vector , then, with classes, your output is
Where and .
What is a template (for a linear classifier)?
A linear classifier, in the case of images, learns a template image for each class because each row of the matrix multiplies the input to get an output for the row corresponding to the class. So row 3 in for class 3. The visual aid below should help:

What are 3 hard cases for linear classifiers to recognize?
- XOR type relationships, since it cannot draw a line between it.
- A ring of points.
- Multiple modes/circles of points
See the image below.

What is multiclass SVM loss?
Basically a hinge loss function, where the prediction of the correct class must be stronger, by some margin, than the next most likely prediction.
Though shown as the sum of all differences + margin for all classes.
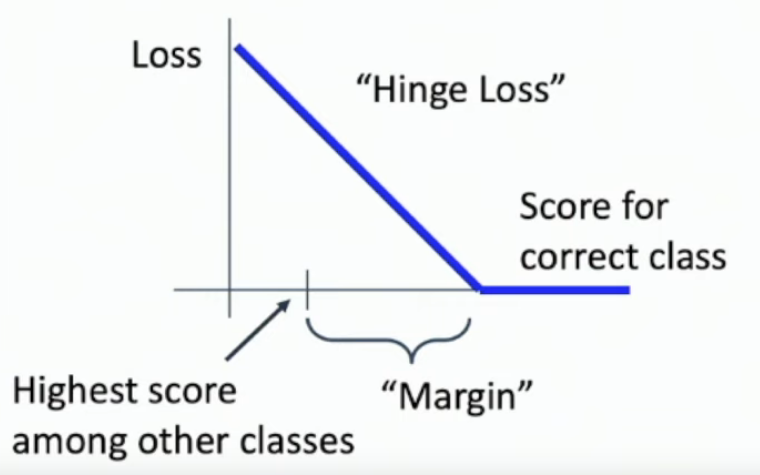
What is the expected multiclass SVM loss for newly initialised matrices?
Since all values are randomly generated around some small standard deviation, the average difference between points is 0, and so the size of the margin multiplied by num_classes - 1 (since we don’t count the correct class).
let be the margin and be the number of classes, then the initial loss should be
What is regularization? And how does it relate to the loss function?
Regularisation is the mechanism by which we can prefer our matrices and bias vectors to be a certain shape and size; specifically simpler and smaller. In terms of loss thats
Where is the true output, and .
What are 3 (simple) forms of regularisation?
L1, L2 and elastic net, which is some weighted average of L1 and L2.
L1:
L2:
What are logits?
outputs that have not yet been exponentiated and normalised, in the context of softmax output.
Why is the softmax function called softmax?
Because it’s a maximising function that can be differentiated.
What is cross entropy loss?
If you get the softmax of your output, where is the prediction probability of the correct class, loss is
What is some of the math behind why cross entropy loss is -log(prob_correct_class)?
Something about the equation used in Gibbs’ inequality from information theory:
What is the expected cross entropy loss from initialisation?
Where is the number of classes
Reading - CS231n Linear Classification
Why is bias useful? (hyperplane perspective)
From the geometric view, it makes sure that not all hyperplanes which separate categories go through 0, since this would reduce accuracy.
What is the geometric interpretation of changing weights?
They translate, rotate, etc.. the hyperplanes which cut up the vector space into sections that signify specific types of objects.
What is data normalisation?
Subtracting every example by the mean of the data and then dividing by the standard deviation of the data.
Lecture 4 - Optimisation Methods
What is random search for minimising loss?
Picking random weights and choosing the ones that perform best.
What is a gradient?
in multiple dimensions is a vector of dL/dW, for each W_i.
What is a numerical way of calculating the descent gradient?
- Get the loss, given the random set of weights.
- Update one of the weights with a small step h.
- Calculated the loss from this updated weight matrix.
- dL/dW for that updated weight is (old_loss - new_loss)/h.
- Repeat for all weights.
When would we want to use the numerical gradient?
To confirm that our analytic methods work, by checking that the difference between the two gradients is less than some small (epsilon) value.
What are some PyTorch tools for making sure you’ve implemented a gradient properly?
torch.autograd.gradcheckand also, to check that your second derivatives are okay you can use
torch.autograd.gradgradcheckif both pass, you don’t need to check any more gradgradgrad*check, since the previous functions account for that.
What are 3 hyper-parameters for total batch gradient descent?
- learning rate
- number of iterations
- weight initialisation
What are 2 more hyper-parameters for mini-batch (stochastic) gradient descent?
- Batch size
- Data Selection
What SGD problems does SGD+Momentum solve?
- Getting stuck in local minima
- Getting stuck in saddle points
- Having poor conditioning numbers.
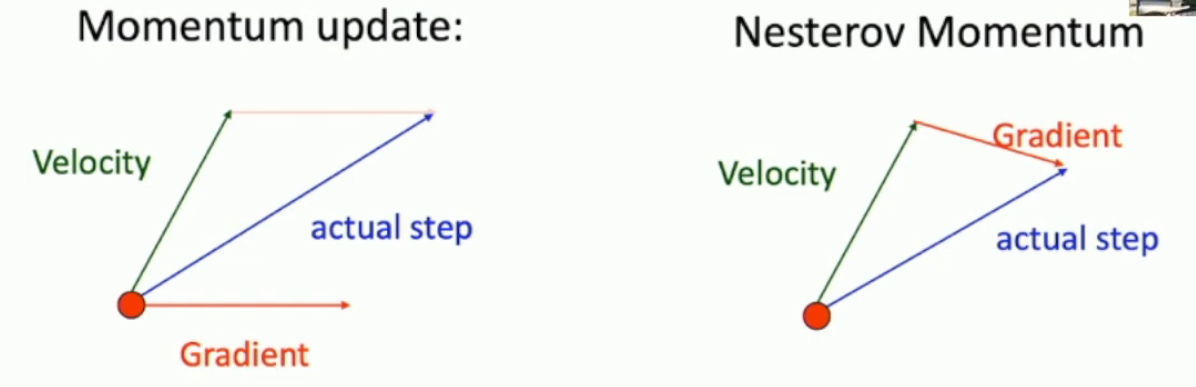
What is Nesterov momentum?
Essentially the same as SGD momentum, but rather than looking at the gradient from where our weights currently are, it looks at the gradient of the point where the weights would be if they moved in the direction of velocity.
What problems does AdaGrad solve?
Overshooting when faced with poor conditioning.
What is does is it divides by the square root of the squared weight gradients (plus some epsilon).
So if one direction is really big, it divides by that and gets a smaller step in that direction, and if one direction is really small, it divides by that and makes the step bigger.
What problems arise from Adagrad? How are these solved with RMSProp?
Since the squared gradients are added on, at every iteration:
grad_squared += dw*dweventually it’s going to get quite big, which means our step sizes will get smaller and smaller, until they might be too small to make any further optimisation.
To overcome this RMSProp decays grad squared every time:
grad_squared = decay*grad_squared + (1-decay)*dw*dw
What is Adam? What are some good initial settings for Adam?
Adam is a combination of RMSProp and SGD Momentum.
Both the velocity and grad_squared are decayed at each update.
We have to also divide out velocity and our grad_squared by (1-beta1**t) and (1-beta2**t) respectively, where t is the timestep/iteration.
Good settings:
- beta1 = 0.9
- beta2 = 0.999
- lr = 1e-4, 5e-4, 1e-3
What is second order optimisation?
Use Hessians to find the minimum point you can travel to from your current location.
This involves manipulating a Taylor series to find the new value of W.
Which 2 optimisation algorithms are best?
Adam and SGD+Momentum, sometimes SGD+Momentum outperforms Adam with some tuning, but Adam is a great starting point.
Reading - CS231n Optimization
Are mini-batches computationally faster or slower than SGD?
Faster. Many AI algorithms have become optimised for mini-batches.
What batch sizes (1, total, or somewhere in between) are used in practice?
32, 64 or 128 is common. One of the best convnets used 256.
Powers of 2 are good because the algorithms in many AI libraries are optimised for powers of 2.
Reading - GBC 8.1 to 8.6
What is a difference between conventional optimisation models and those used to train neural networks?
Neural networks are not convex, their landscape is multidimensional and optimisation is incomplete in that we are happy with a ‘low’ point in the landscape that isn’t necessarily the global minimum.
A category of conventional optimisation is convex optimisation, which has one minimum, which is the global minimum; neural networks are very different from this.
What is risk? (seems like a niche keyword)
The generalisation loss.
The dataset is always pulled from some data generating distribution, and the true distribution is what is measured against for final accuracy, aka unseen data.
The ability of a neural network to reduce risk is it’s ability to properly identify the underlying properties of the data generating distribution.
What is empirical risk minimisation?
Since we are working with datasets, which will always be incomplete, there are more or less an infinite number of possible t-shirts, but all are t-shirts.
Our ability to minimise loss over our dataset is minimising empirical risk.
What is a surrogate loss function?
A highly-spoken-of function is the 0-1 loss, where 0 is what we get if it’s wrong, and 1 is what we get if our prediction is accurate. This derivative of this function is 0 everywhere, this doesn’t help backpropagation, so we use placeholders, like the sigmoid.
I’m unconvinced by 0-1 loss being great, it’s just a matter of classification, and the aim is to actually minimise a different function, like ReLU output or softmax output, and once those are ‘optimised’, we can classify with a 0-1, or one-hot classification.
Why shuffle data?
The order of the original dataset may be meaningful, like the first 3 bloodtests are by person a, then the next 5 are by person b, but we want to be able to identify a random bloodtest.
So we shuffle the data to destroy any meaning in the order.
Why might using full-batch be inefficient?
- The dataset is huge.
- There may not be duplicates, but many examples will be very similar and there isn’t much use using them twice in the same training step.
- Storage might be an issue.
How many high-cost local minima might a neural network have? Is this a problem in practice?
Not many, most local minima are lower down, aka, closer to the global minimum, so this isn’t a problem in practice.
Just by definition there are likely to be more global maxima in high-cost areas.
saddle points may be problematic.
How can you check if you’ve hit a local minima?
If the gradient is very small, usually by getting the norm.
What are cliffs and exploding gradients? How can you avoid their (potentially) bad impacts?
the loss landscape may have cliffs, that may be climbed up as well as climed down, however the problem of overshooting a cliff and ending up in a higher region, due to the high gradient is an issue.
This can be solved partly with gradient clipping, maybe normalising the gradient by it’s norm.
What types of networks are most affected by vanishing and exploding gradient?
RNNs, since they are lower dimension, and higher dimension spaces tend to have more opportunities to ‘walk around’ cliffs.
How common are local minima and saddle points?
Actually not that common.
What is a condition on the learning rate to ensure SGD converges?
Where is the learning rate at each timestep . This model suggests that the learning rate needs to decay over time. seems like 1/k, the harmonic sequence might be good 🤷♂️.
How would you choose an optimal learning rate?
Hyperparamter tuning, but also, look at the learning rate that performs best on the val set, then go a little higher.
In what case might Nesterov momentum outperform classical momentum?
In the full-batch case.
What is (Martens’) sparse initialisation?
Every node is connected to only k nodes from the previous layer, and this is true for every layer.
How might you ensure that your initialisations are good?
Check that the mean and sd at each layer doesn’t eventually vanish during forward prop, and the same for gradients in backprop.
The main aim of good initialisations is that your network can start in a good place that’ll lead to a low cost point.
What are some conventions for initialising bias vectors?
- Set it 0s
At the output layer, where is the average initial output vector, so where is the number of classes, set
and rearrange for , and that’s your bias vector, where Softmax is used at the output layer.
What are some non-random forms of initialising parameters?
- Normal or Uniform small values.
- Xavier, , where is the number of nodes in the previous layer, and in the next. Or .
- Kaiming He, , where is the number of nodes in the previous layer. Or .
- Weight matrices have all orthogonal vectors.
In the simplest terms, what is a second-order optimisation method?
One that uses second derivatives.
What is the second order Taylor expansion of our loss? And how is Newton’s method for second order optimisation found from there?
So just the first 3 terms in the Taylor expansion of the cost function, where is the Hessian.
The newton update is
What property must the Hessian satisfy for Newton’s method to work? How might we change the Hessian so that this is satisfied?
All eigenvalues need to be positive, so we can just add the identity matrix over and over until the gershgorins disks move far enough that all are positive.
What are some drawbacks to Newton’s method?
- It takes a very long time to compute an inverse, which takes computations, where is the number of parameters.
- Adding the identity to the hessian too much can make it lean in a weird direction.
Lecture 5 - Neural Network
What is a feature transform?
i.e. Cartesian → Polar
It essentially means applying some functions to the input so as to extract some meaningful information.
This is essentially what neural networks learn to do, but it days gone by they used to think up manual methods for this.
What is a colour histogram for CV?
Get the colours in an image and lay them out in a histogram, for some set number of colour bins. Red, green, blue might be 3 main ones.
This is one form of feature transformation.
What is a Histogram of Oriented Gradients (HOG)?
Get the gradients at 8x8 grids over an image and get histograms of where the edges point, apparently 9 was a good number, 1 for flat, 8 in all other directions.
So a 320*240 image would be converted to 40*30*9, the 9 comes from the 9 bins.
This is one form of feature transformation.
What is a bag-of-words approach to image feature transformation?
Express an image in terms of the features it contains, like hands, eyes, etc. rather than only the image. This seems computationally expensive. they would need some sort of KNN to see if a hand looks enough like a hand to be extracted.
What is a downside to feature extraction?
- Training and identification may be longer.
- You have to decide on the feature extraction mechanisms you want to use, and that might be arbitrary.
- You train the network (post-feature-extraction) on your feature extractions rather than the image itself, so there’s a layer of (potentially inappropriate) abstraction between the network and the image.
- The network can learn the relevant features anyway
Although it has it’s downsides, pre-CNN it was the most effective form of image recognition.
What is an MLP?
Multi Layer Perceptron = A neural network. Same thing. Just some Jargon.
What is a common property of images that a neural network might learn at the first layer?
Edges and their properties.
What is network width? and how is it conventionally initialised?
The number of units in a layer.
Conventionally all layers have the same width.
How do activation functions allow us to build much more complex models than linear classifiers?
Without activation functions, multilayer linear classifiers can be expressed as single layer classifiers.
But adding an activation function makes it non linear:
Why aren’t biological neurons the same as perceptrons?
- The activation functions are likely far more complicated
- They may connect and reconnect in patterns that aren’t like the input → layers → output model we have.
What is space warping? How do activation functions help to carve up the space?
Changing the space so that we can draw lines through it, this is done with linear mappings ( and activation functions.
How can a ReLU neural network approximate any function? (Universal approximation)
By making little blocks, which can get added up, though usually this doesn’t happen. It’s just a theoretical argument that doesn’t reflect what really happens in NN.
What is a convex function?
One minimum is the global minimum, no other critical points. Like a bowl.
CS231n - Neural Networks
What is maxout?
GBC Reading - mostly skipped bc too much notation that threw me off.
Lecture 6 - Back-propagation
Why would you want to view your model as a computational graph when computing gradients?
It helps to piece things together better.
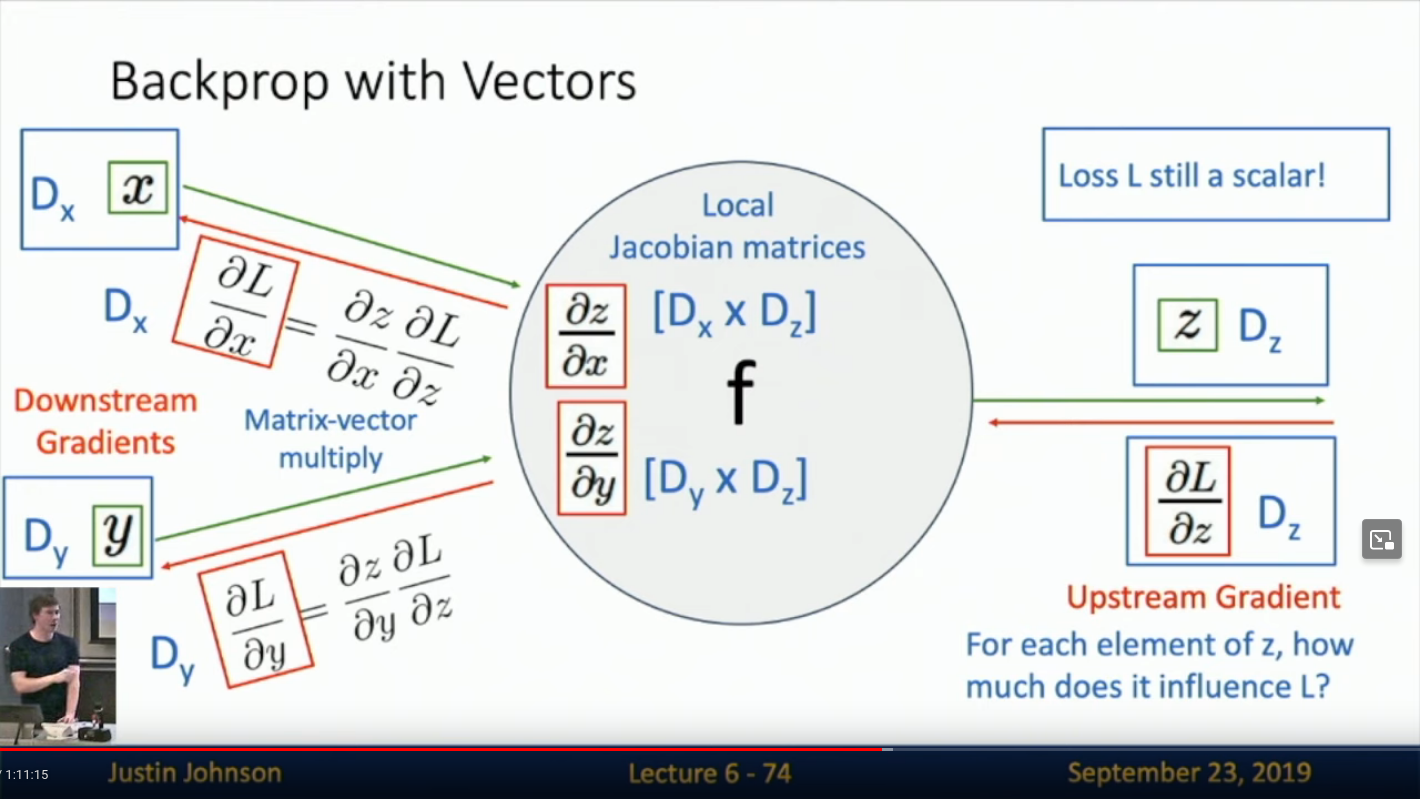
How do you back-propagate with vectors?
Using Jacobians, then rearranging so that the dimensions make sense.
What is the back-propagation step for a perception with incoming upstream gradients?
Lecture 7 - Convolutional Neural Networks
What is an activation map?
A 1XD1XD2 output of the filter going over the input.
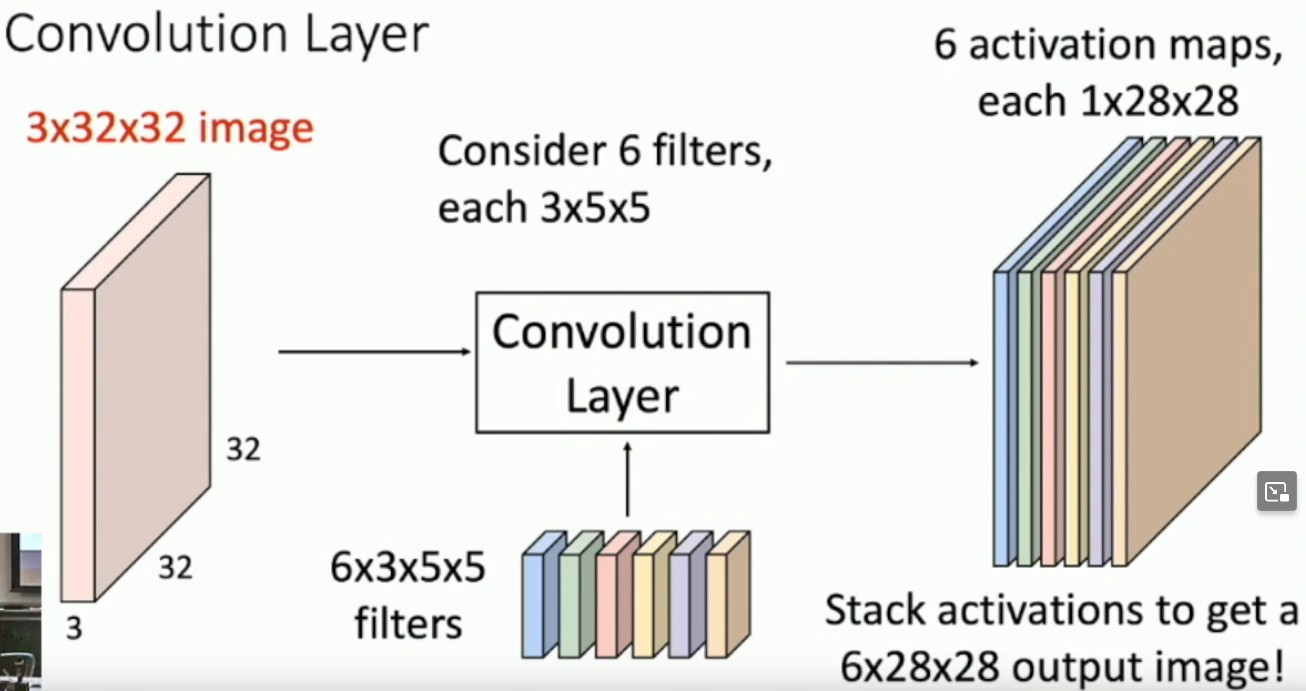
What are 2 interpretations for what activation maps represent?
- A representation of a learned filter of the image. (I.E. potentially learned Sobel operator)
- A representation of how activated each image is by each filter.
What do filter weights look like when visualised?
Funky.

Why, and how would you pad an image?
If you want to preserve the spacial dimension of the image, you can pad it with 0s around the border. You can also pad with by reflecting the image.
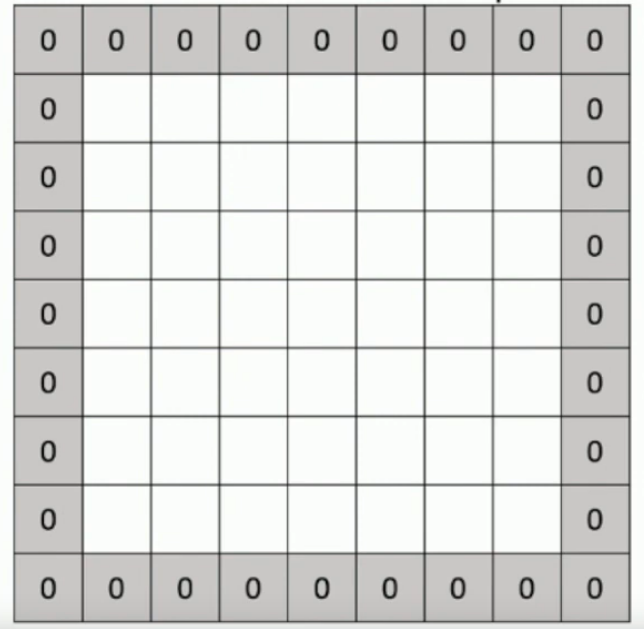
What is same padding?
When the inputs are spatially the same as outputs.
When padding is (filter_size - 1)/2.
What is a receptive field?
The values that go into producing an output for a CNN.
This can be the values in layer 3 that make an output in layer 4 in a 10 layer CNN.
It could also mean the values in layer 1 that contribute to an output in layer 9 in a 10 layer CNN.
What are 7 common practices for implementing CNNs?
- Same padding
- Small square filters
- Powers of 2 for depth size
Filters are usually size:
- 3x3
- 5x5
- 1x1
- 3x3 with stride 2
What is the differernce between 1D, 2D and 3D convolutions?
2D is what we’ve seen so far.
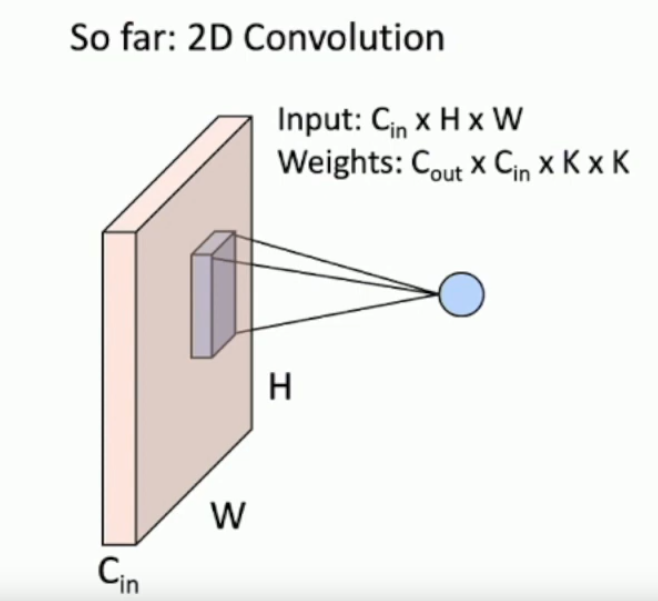
1D is a strip that goes over a 2D image.
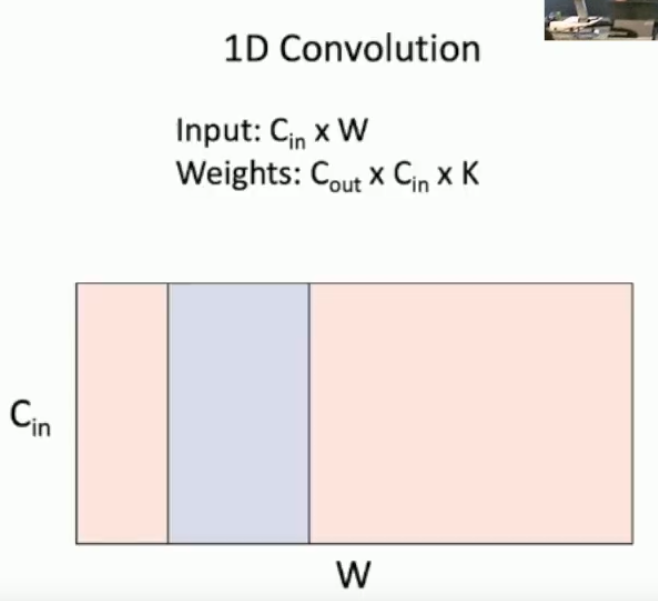
3D is a 3D filter that goes through multiple 3D activation maps, and produces multiple activation maps.
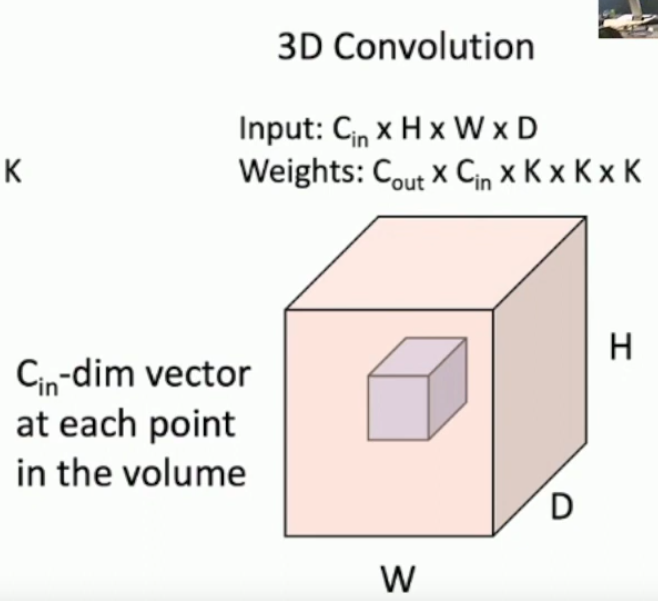
What are 2 use cases for 1D convolutions?
- Text.
- Music waveforms.
What is 1 use case for 3D convolutions?
Point cloud data = 3D data.
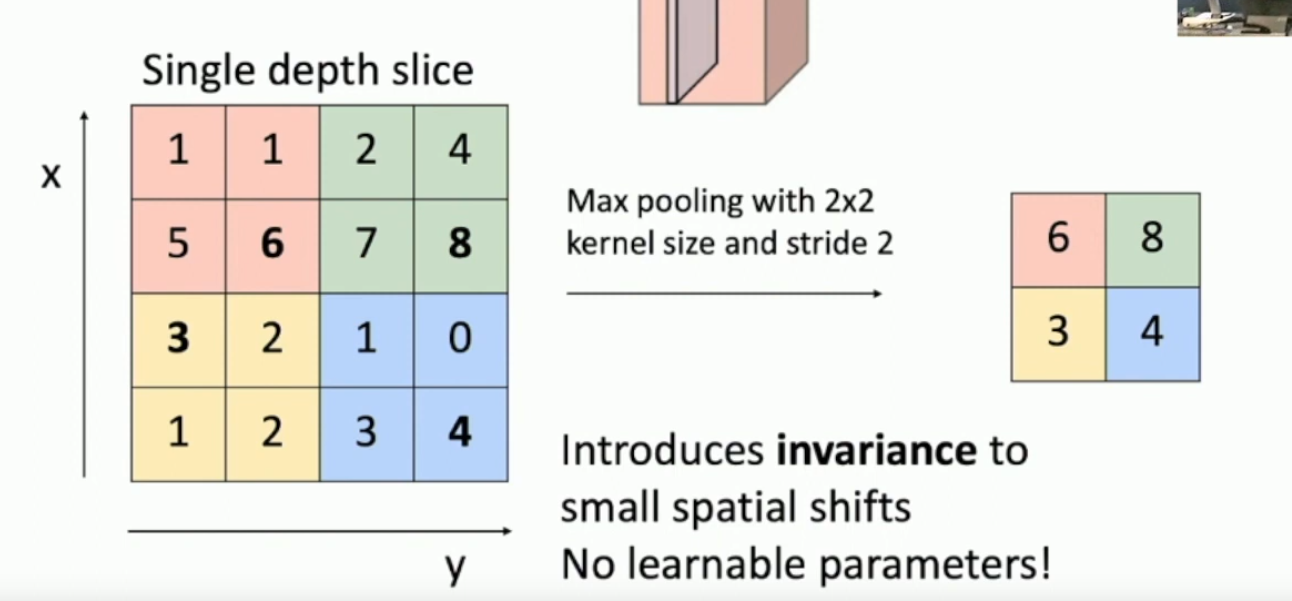
What is pooling?
Downsampling the input, i.e. when you reduce the spacial dimension of an image, and preserve the depth.
Max pooling or average pooling are common.
Below is an image of max pooling.
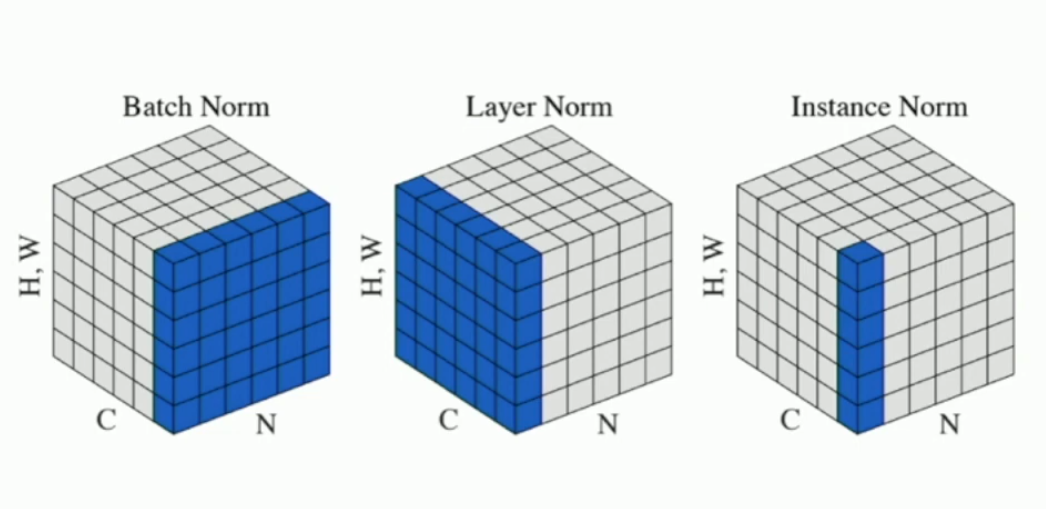
What is batch normalisation?
When you get the average pixel value per channel over all examples in the batch, to produce a mean (and similarly a SD) along the channels.
Mathematically, our outputs are normalised as
For CNNs, the means and SD are , so the averges are per channel, over all examples in the (mini) batch.
What learnable parameters can be used in batch normalisation?
After normalisation:
We let the network relearn the distribution it would like to see with
where the learnable parameters are Note that the means that we can relearn the unnormalised distribution if we learn and .
How should you use batch normalisation at test time?
Since we don’t usually test in batches, we might collect running averages of , over training.
What are 5 pros of batch normalisation?
- Allows for high learning rates, making training faster
- Networks are more robust to initialisation
- A form of regularisation
- No additional computation at test time, since it can be incorporated into final filter weights, since running averages are constants in the end
- Just easier to train
What are 2 cons of batch normalisation?
- Theoretical understanding is not fully there, weak idea of why it works well.
- Behaves differently during training and testing.
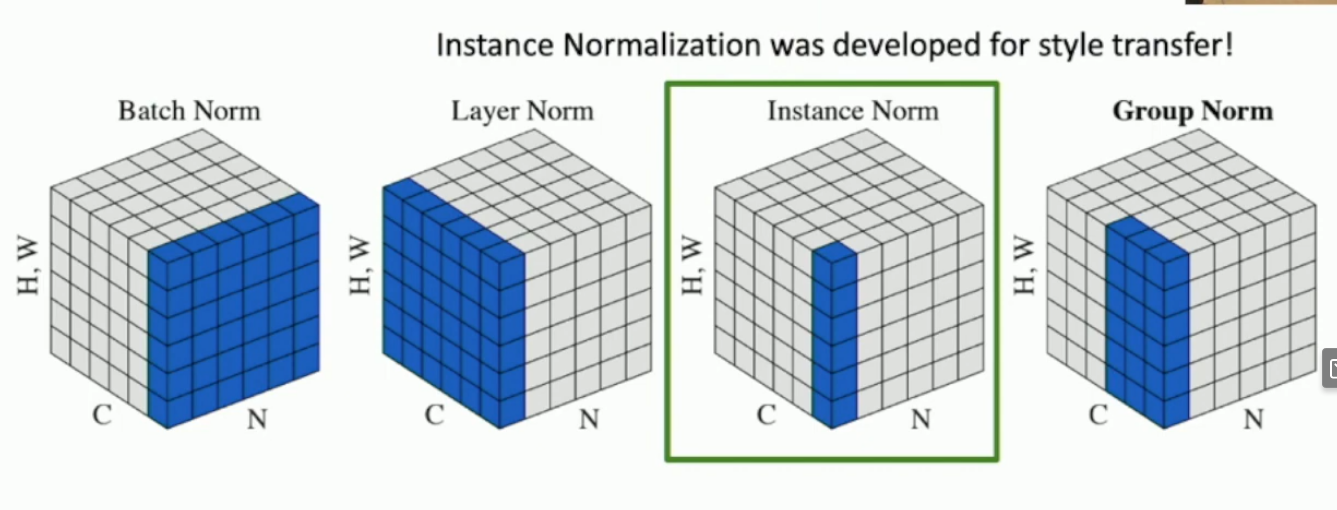
What is layer normalisation? What is instance normalisation?
Layer normalisation takes averages over all values within examples, so it only preserves the number of examples in a batch. So it transforms .
Instance normalisation takes averages over the spatial dimensions but not over the whole batch. So it transforms .
Picture of normalisations
CS231n Convolutional Networks
What is dilation?
a 3x3 filter with gaps between elements in the filter, so it technically becomes a 5x5 filter with gaps.
Which pooling operation, filter size and stride are most commonly used in practice?
2x2 Max pooling with stride 2.
Which is the preferred form of downsampling, pooling, or convolutions (with larger stride)?
Convolutions.
What happens if you feed a larger, but compatible, image through your CNN? How do you find it’s output?
Say we have imagenet, with 1000 classes, our usual output might be 1x1x1000, but with a larger image that might be 6x6x1000.
What you do there it up to you, you could average it, or get some norm of each of the 6x6 matrices.
Which stride should you usually use?
1 - It works best.
In terms of memory, what sort of compromises might need to be made?
You may need to use large filters with large strides on the first layer, where the image is large.
Lecture 8 - CNN Architectures I
What was new about VGGs implementation of CNNs?
They systematised it, so less trial and error.
What are FLOPs?
Floating point operations (rearranged to have a nice name).
Number of computations = multiply-adds.
Even after batch normalisation, what caused the issue with training deep networks?
Bad optimisation, even a 52 layer network underperformed a 20 layer network, both in test accuracy and train accuracy.
A 52 layer network ought to learn the functionality of a 20 layer network anyway, so why would it underperform? Bad optimisation, solved with residual blocks.
What is a residual network?
A network composed of residual blocks.
What types of residual blocks are there?
Plain:
x → CONV 3X3 → CONV 3X3 → f(x) + x
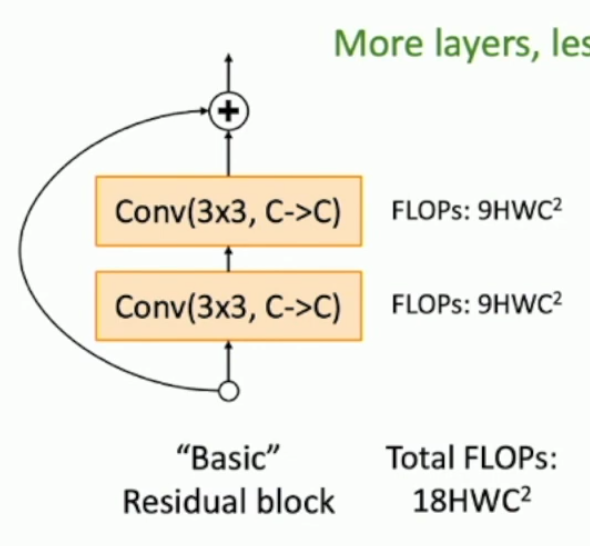
Bottleneck:
x → CONV 1X1* → CONV 3X3 → CONV 1X1**→ f(x) + x
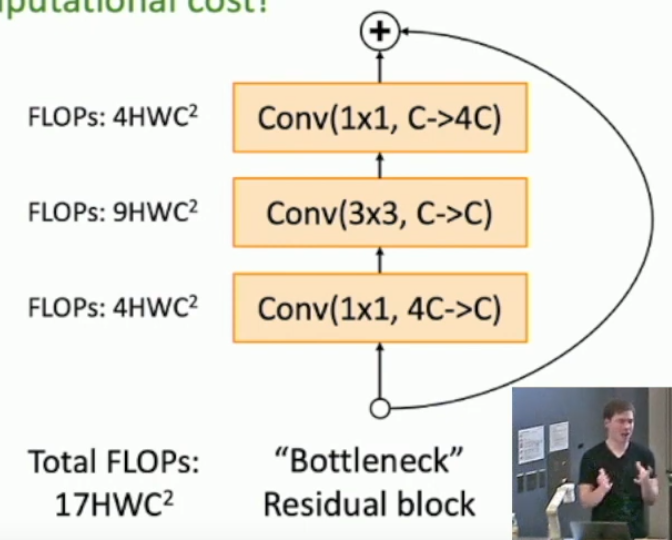
*Decrease number of channels.
**Increase number of channels to previous size.
What are properties to look for (or make) in CNN design?
- Can be made very deep
- Is systematically* designed
- Fast computations
- Less memory
- Fewer params**
*Rather than trial and error, AKA voodoo magic AI man.
**Less necessary, except as a memory problem.
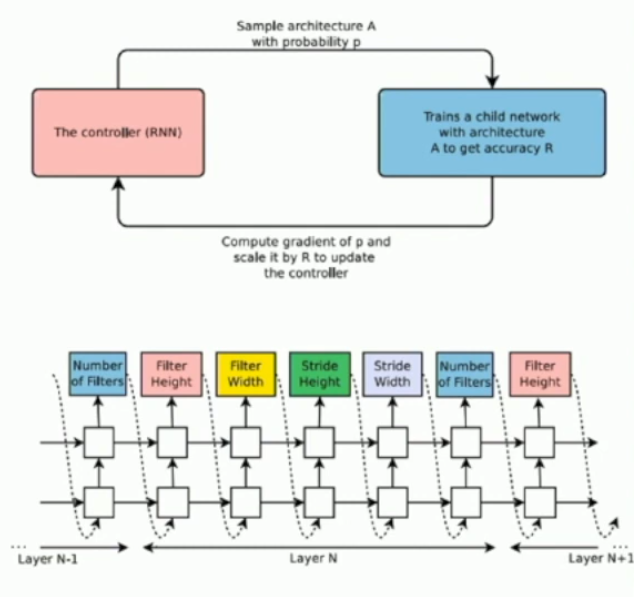
Can you find neural network architectures using a neural network?
Yeah, initial attempts were VERY expensive, but later attempts were less expensive. These methods produced better architectures than some that were out there.
Lecture 9 - Training Neural Networks I
What is zero centring?
Activations are centred between positive and negative at 0.
Sigmoid and ReLU are not zero centred.
LeakyReLU is.
What are 3 problems with sigmoid?
- Saturating edges
- Not zero centred
- Computationally expensive exp()
What improvements on sigmoid does tanh have?
tanh is zero centred, that’s the only improvement since tanh is technically a shifted and scaled sigmoid.
What are 3 pros of ReLU?
- Non saturating gradient for x positive.
- Computationally cheap/fast
- Converges on average 6x faster in practice than sigmoid/tanh.
What are 2 cons of ReLU?
- Not zero centered.
- Gradient is 0 for x negative, creating dead zones.
What ReLU problems does LeakyReLU solve?
LeakyReLU is zero centered and doesn’t have dead zones.
What LeakyReLU problem does PReLU solve?
PReLU leaks the hyperparameter which decides how leaky LeakyReLU is.
What is the ELU?
x for x>0.
exp(x) - 1 for x<0.
for x<0 you might want to scale it, but thats just another hyperparam to worry about, so never mind.
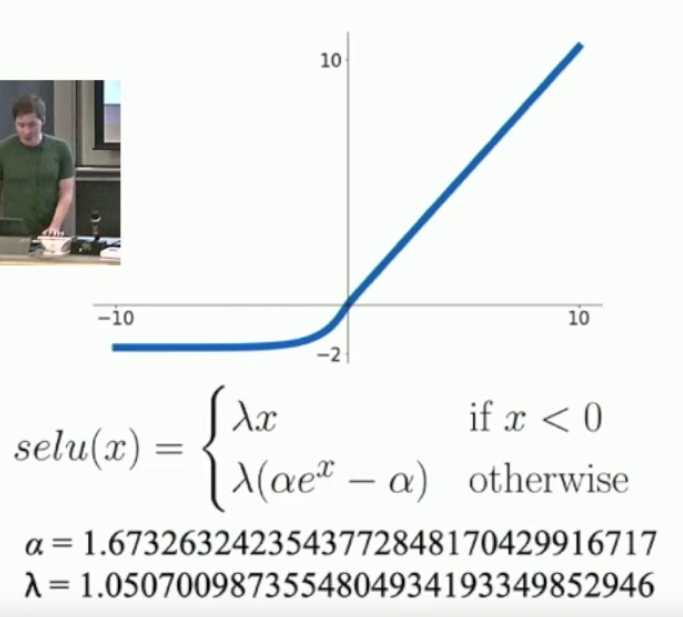
What is SELU?
It’s a specifically parametrised ELU:
It has a self-normalising property so you do not need to use batchnorm with it.
What is Swish?
Think about it.
Which activation function should you use in practice?
ReLU, then try some extra ones if you want to squeeze out a little extra performance.
But as you can see, it doesn’t matter too much:

What preprocessing does ResNet use?
Per channel mean and SD is found and normalises all images.
What is the notion behind Xavier initialisation?
Variation of inputs should equal variation of outputs.
What is Kaiming initialisation?
How are residual networks initialised?
First conv layer in a residual block is Kaiming, remaining conv layers set to 0.
What is inverted dropout?
It’s dropout, but you rescale during training. So you divide the remaining outputs by the probability that they remain. So that they’re proportionally stronger. Then at test time you don’t do anything with dropout probability.
Where would you use dropout in a CNN with FC layers?
On the FC layers, fully convolutional networks do not have dropout. It is less common to see dropout generally.
What is data augmentation?
For images, it’s making little changes:
- Flip the image
- Take random crops of the image, or predetermined crops
- Scale the image
- set random sections of the image to 0 (cutout)
What forms of regularisation are there?
- Dropout
- Drop Connect (set random weights to 0)
- Batch Normalisation
- Data Augmentation
- Fractional Max Pooling
- Stochastic Depth (vary the depth of your network)
- Cutout
- Mixup (5% cat + 95% dog blended image)
What are the main 5 forms of regularisation?
- Batch Normalisation
- Data Augmentation
- Mixup
- Cutout
- Dropout (used less)
Lecture 10 - Training Neural Networks II
What is cosine learning rate decay?
Where is the current timestep and is the final timestep.
What is a linear learning rate decay schedule?
lr decreases linearly over time.
Which lr decay schedule do people in CV tend to follow? What about NLP?
CV often uses cosine, and NLP often uses linear.
These decisions are just observations/conventions.
What is inverse square root lr decay?
What is the best way to approach lr deacy?
Start with no decay, then once you find a good learning rate, use some decay and see if that improves your model.
You can also do random search
What is early stopping?
Over the course of training, you may overfit, so every few epochs (say 2, or 4), you can save your model parameters. Then looking at the training vs validation accuracy you can see where validation accuracy was highest, pick the model params in that region.
Note, your validation accuracy may always be increasing or may plateau, although not covered in lecture, it’s clear you should still pick the highest accuracy, even if that’s your latest model.

Grid search vs Random Search?
Random search can illustrate which hyperparameter is more important, and you should do a finer search of the more important hyperparameter. The more important hyperparameter will have a stronger effect on the marginalised network accuracy (depicted by the graphs with circles on them on the edges of the grids).

What are 7 steps to follow hyperparameter search?
- Check things are initialised properly by doing a sanity check on what the loss should be. (i.e. softmax loss should be 2.3 for 10 classes right at the start)
- Overfit 5-10 minibatches of data as quickly as possible, with the right learning rate. If you can’t do this, then you have no chance of fitting the actual data. Model works-well check.
- Find a that makes the loss go down very fast. in ~100 iterations, with a little decay.
- Do a course search - Train your network with a small random search on 1 to 5 epochs. Choose the same decay from step 3.
- Do a refined search - Train your network with a finer search on the important hyperparams for 10 to 20 epochs. No decay.
- Check learning curve graphs.
Suggestions for plotting a loss curve?
Make a scatter plot and a moving average.
What relevance does the weight-update:weight-value ratio have?
Should be around 0.001:1. I think this is a heuristic.
Are model ensembles useful?
Yes, they usually increase accuracy by ~2%.
What is Polyak averaging?
Getting an average of your weights over train time, to use at test time.
What is transfer learning?
Getting a funny trained CNN, such as AlexNet, and removing the FC layers and use the convolutional layer as a feature extractor for a new network that you train.
So delete, and retrain the FC layers on your dataset.
What is model parallelism?
Running a model through different GPUs.
- You can run the first k layers with 1 GPU, then the next m layers on another GPU, etc..
- (like AlexNet) You split the model lengthways, so each GPU runs over the whole network, but through a slice of it.
What is data parallelism?
With a mini-batch of N examples, and K GPUs, run N/K samples from each mini-batch on each GPU. Really speeds up training time, you can look up ‘training ImageNet in 1 hour’ or even ‘ImageNet in 15 minutes’, though the batch size and training time are linearly correlated, and so basically more GPUs = faster training.
Lecture 11 - CNN Architectures II (slides only)
What is grouped convolution?
When you use some filters on some channels of the input and not others.

Why use groups?
They might improve performance.
What is a Squeeze-and-exite network (SENet)?
Add some more operations to a residual block.
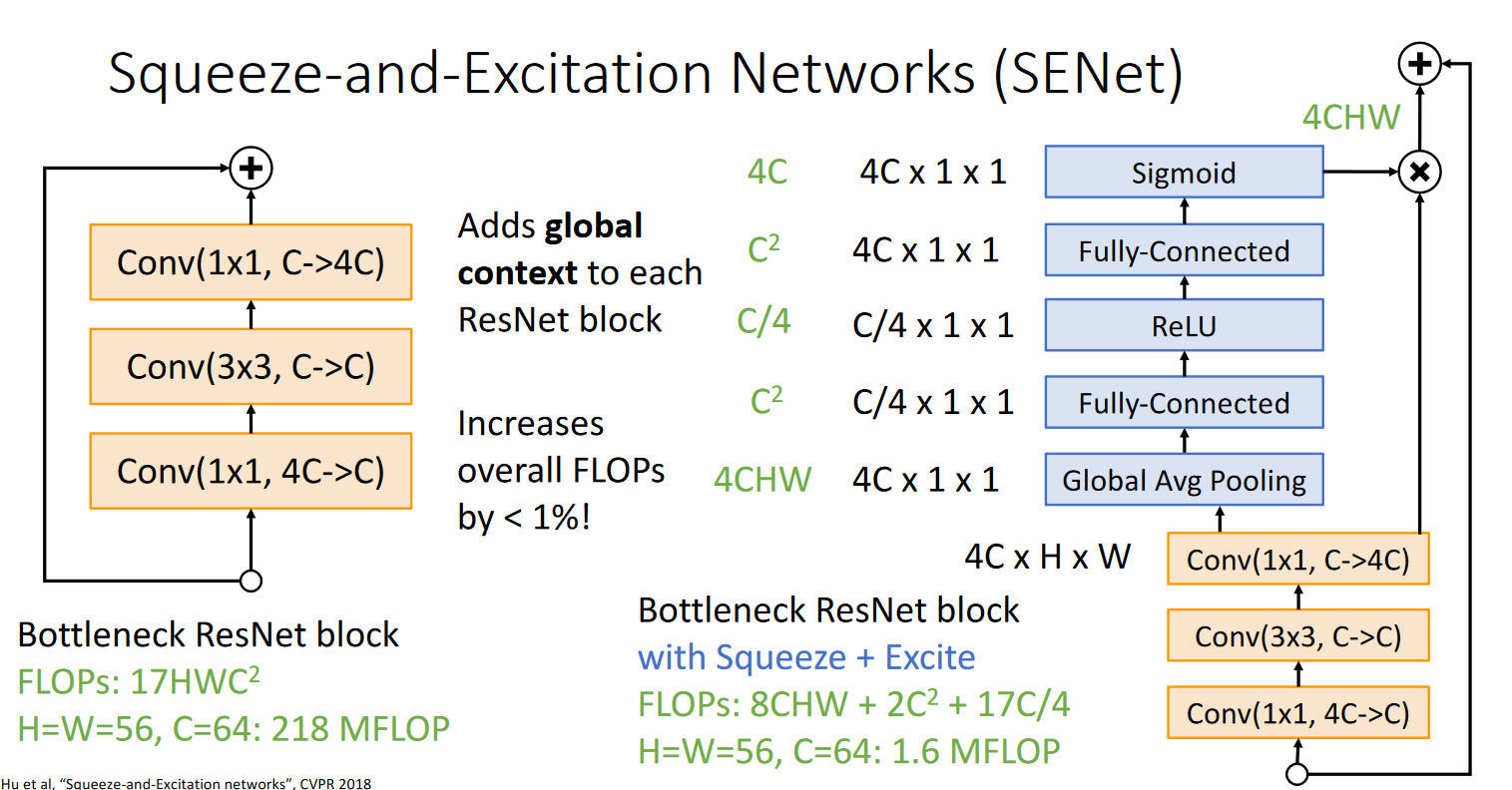
What are 3 forms of model scaling?
Width, Depth, input resolution.
Lecture 12 - Hardware and Software
What are tensor cores?
Cores in a GPU that do 4x4 matrix multiply-adds. i.e. AB + C, for matrices A, B, C.
Very fast for matrix multiplication, only uses float16 for multiplication, and float 32 for addition, which means it’s mixed precision.
How to use tensor cores in newer GPUs?
Set dtype to float16 for your parameters, and enable nvidia, make sure the right drivers are installed and that your GPU actually has tensor cores.
Why are so many sizes in neural networks in powers of 2?
Bc tensor cores, and cores generally, operate in powers of 2. i.e. 4x4 matrix multiply-adds
What is the difference between static and dynamic graphs?
Static graphs are built and stay the whole way through.
Dynamic graphs are built and destroyed at each forward pass.
What are the pros and cons of dynamic graphs?
Pros
- Can make complicated if else progressions for complicated graphs.
- Easier to debug
Cons
- Slower runtime
- Can’t export it
What are the pros and cons of static graphs?
Pros
- Faster
- Can export it
Cons
- Harder to debug
Lecture 13 - Object Detection
How are bounding boxes parametrized?
x,y coordinates and a height and width of the box.
so (x,y,h,w) total.
How do you detect a single object?
Output the bounding box coordinates alongside the classification.
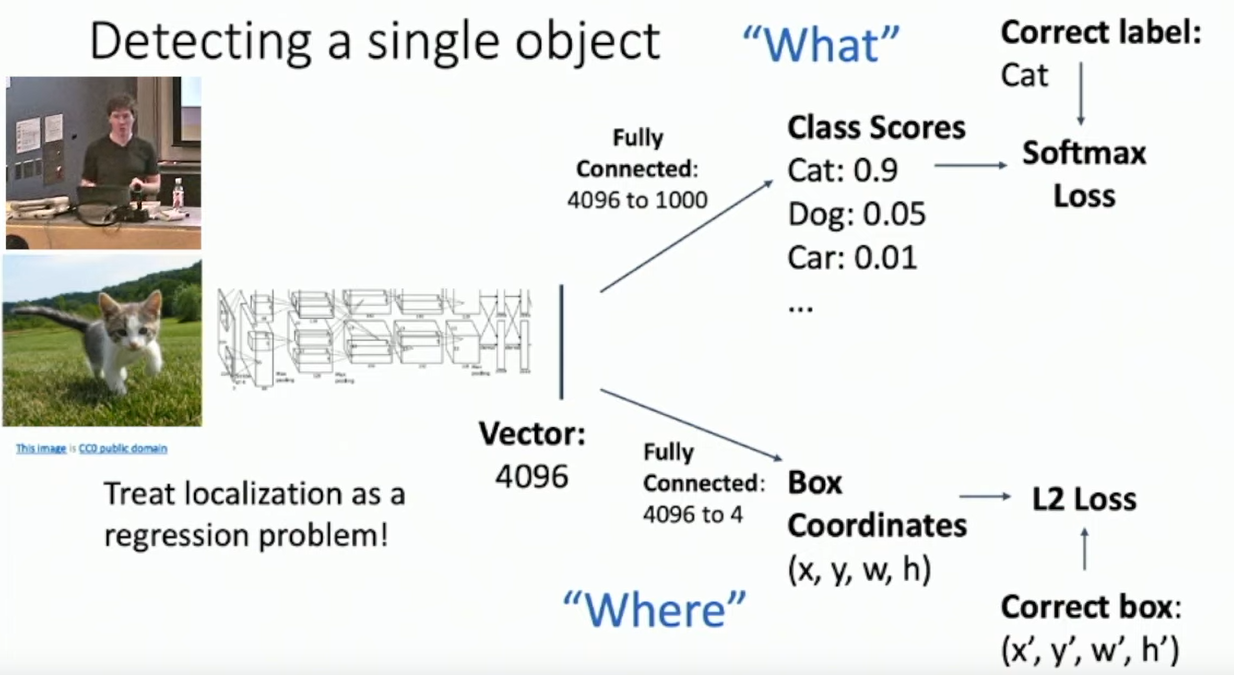
The trouble is calculating multiple object detections
What is the Sliding window (brute force) approach to multiple object detection? cons?
Use every possible bounding box and classify the image ~58 million crops for 800x600 image.
Con

What are region proposals?
Proposed crops of the image that may have something classifiable~ 2K crops. A lot less than 58 million.

What is an R-CNN?
A region based CNN.
You feed each region to a single object detector CNN.
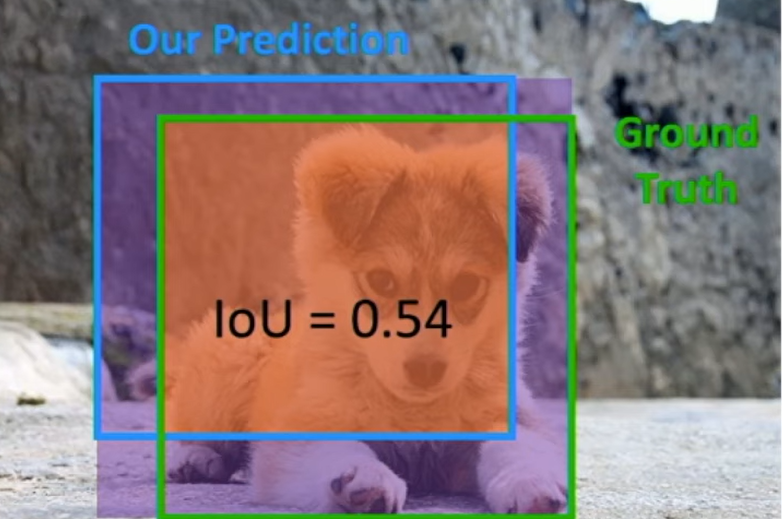
How are predicted and ground-truth boxes compared (IoU)?
You find the size of the intersection between the two boxes and divide that by the size of the box formed by the union of heights and union of widths of the two boxes. This is known as intersection over union (IoU).
What are overlapping boxes and how do we deal with them (Non-max suppression)?
Two boxes might be predicting the same object. If this is the case, then you choose the box that has a better classification score for the object and remove any boxes that have an IoU greater than some threshold with that box.

What is average precision? What is precision & recall?
- For 1 class of classifications, get the bounding boxes and probabilities for that class.
- Sort predictions by probability of class.
- Starting with the highest probability find an IoU > threshold (say 0.5).
- If found, precision +=1 and recall +=1.
- precision is number-of-matching-predictions/number-of-predictions
- recall is number-of-matching-predictions/number-of-ground-truth-objects
- Find your precision and recall and make a graph out of it, and find the area under that curve.
- That’s your average precision.
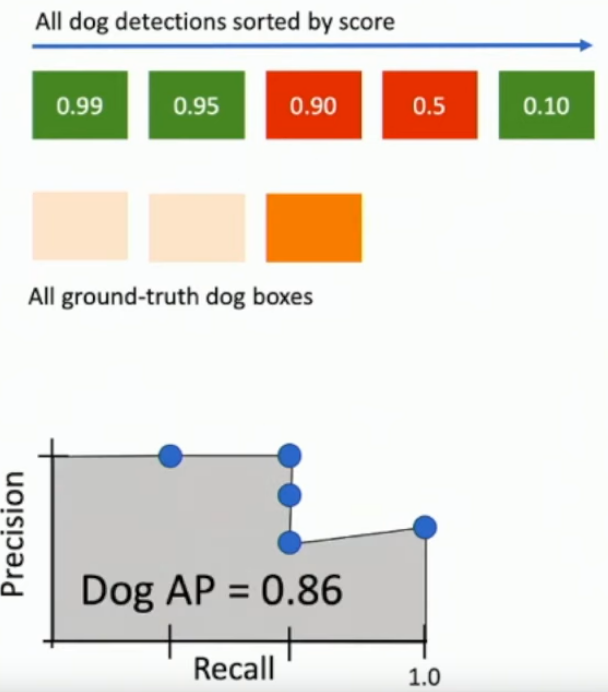
What is mean average prediction (mAP)?
The mean average-precision over all classes.
What is a COCO mAP?
An average over many mAPs at different matching thresholds.
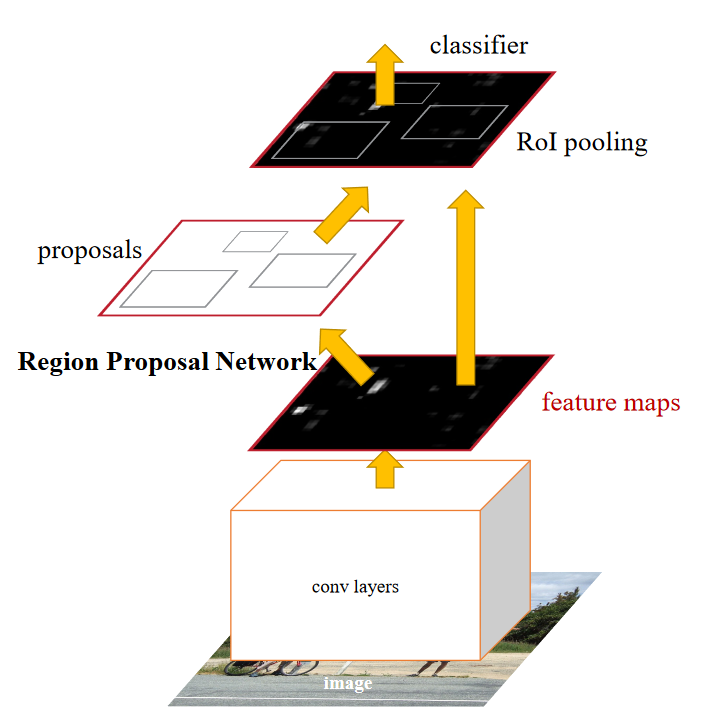
What is Fast R-CNN?
- First you feed the image into a good (backbone) CNN.
- You apply region proposals and essentially follow the same process as “slow” R-CNNs but with much much smaller additional networks.
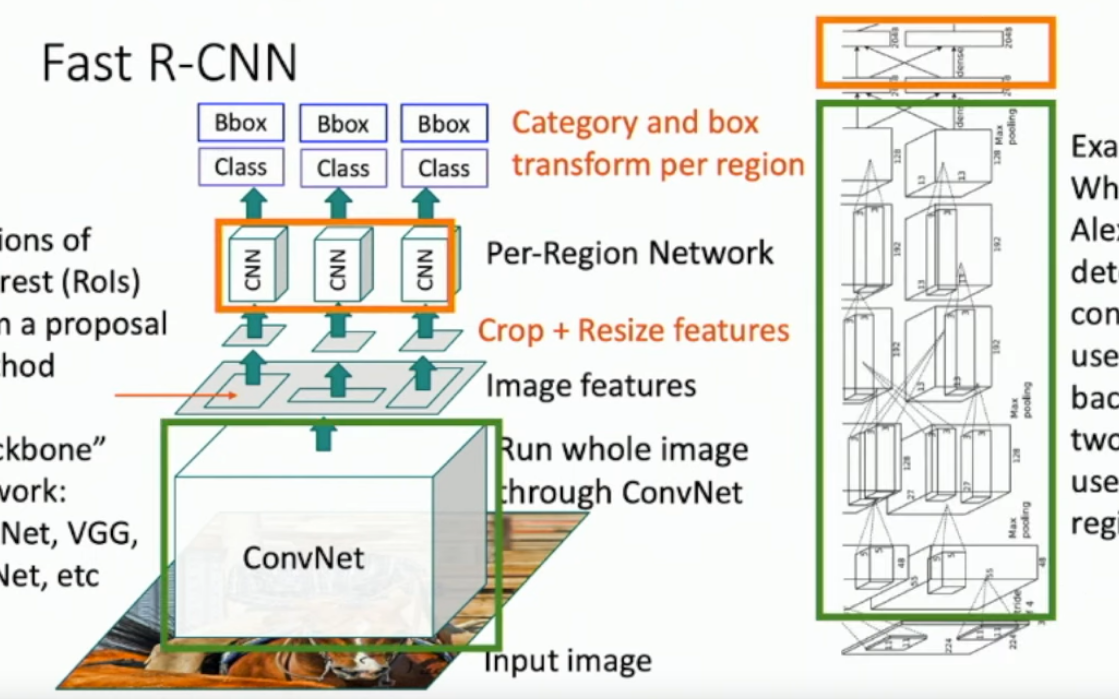
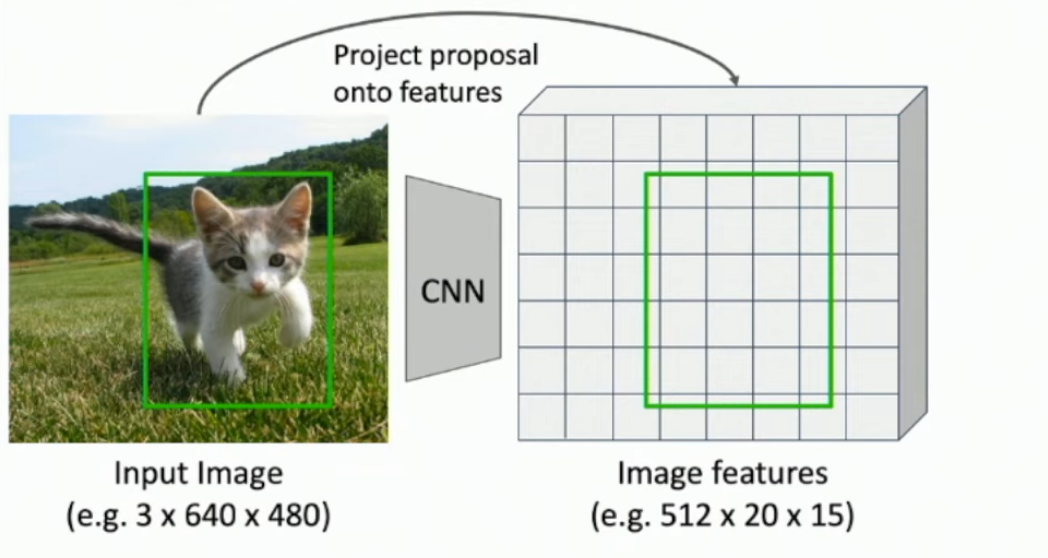
What is RoI pooling?
Region of Interest pooling.
Find your RoIs in the original image, then try to match that bounding box (proportionally) to the HxW output layer of your backbone CNN, along all channels. The bounding box won’t match*, so you ‘snap’ the bounding box to it’s nearest line, cut out by the ‘pixels’ in the HxW view. See the 2 images below.
Then you just apply 2x2 max pooling to that snapped cutout (image 3).
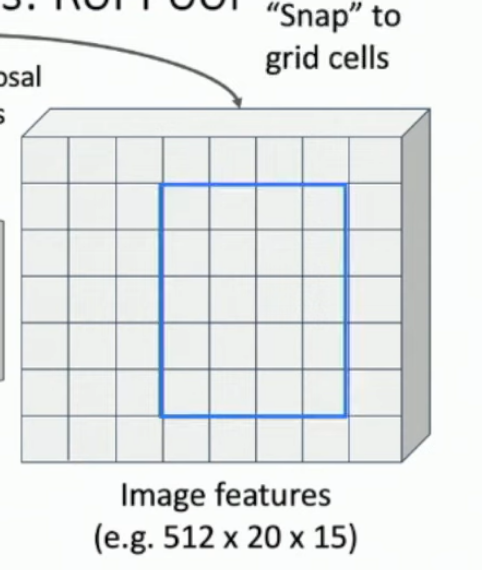
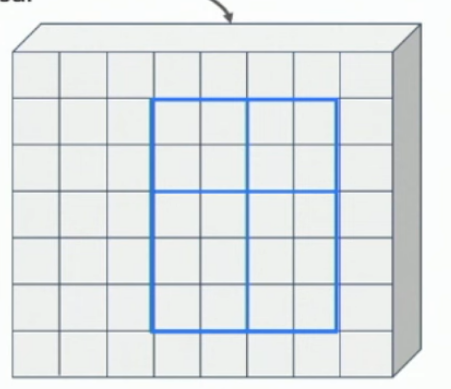
*Unless you go to lecture 15 and look at RoI Align
What is Faster R-CNN? What is an RPN?
Once fast R-CNNs are implemented, most of the time in compute is spent getting region proposals. As always*, we can build a network that idenfies these regions, known as a RPN (Region Proposal Network).
It’s like a mini R-CNN inside the R-CNN. Once we have our image features from our backbone, we can get “anchors” for every point in the HxW, where we see if some region around that point might contain an object. These anchor regions output whether or not it is an object, and the appropriate bounding box to put around it. They also have K different shapes for different shaped objects.
See the images below.
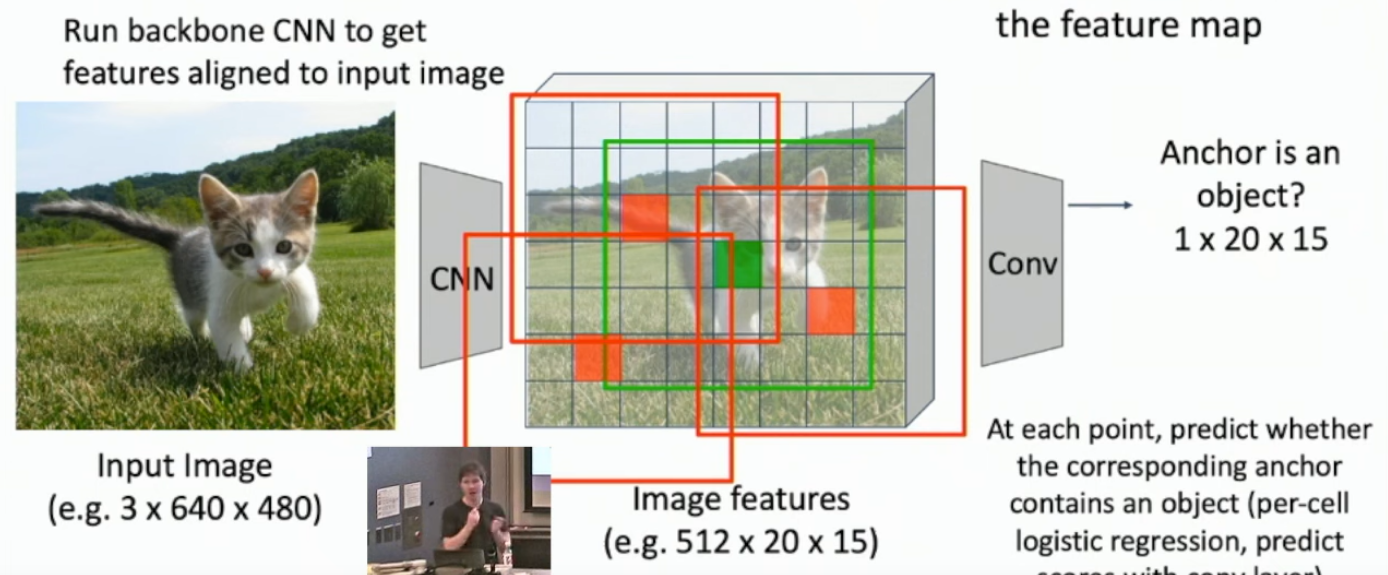

*When in doubt, build a neural network for it.
What is a single stage R-CNN?
Combine the region proposal with the classification of that region, performs faster but worse generally, but these days it’s only a little bit worse than faster R-CNNs.
Lecture 14 - Object Detectors (slides only)
Seems like the only difference from 2019 material are these additional 5 papers*. For completeness, there is also a youtube video as a recommended reading.
Girshick “Fast RCNN” 2015
No notes. Mostly discusses difference with RCNN and SPPNet*. Essentially it does the CNN first, and then does region proposals on the feature map outputted by an intermediate (but late) layer in the CNN.
*Not covered in lecture.
Kaiming et al “Faster R-CNN: Towards Real-Time Object Detection” 2015
In what sense does Faster R-CNN use sliding windows?
They go over the spacial dimension of low level features produced by the backbone CNN.
What is the architecture of an RPN?
nxn convolution*, followed by sibling 1x1 convolutions, one predicting classification (object vs non-object, 2 class softmax), and the other predicting the transformation of the bounding box.
*Basically an elementwise multiplication between matrices.
What are anchors and what are their scales & aspect ratios in this paper?
Anchors are primitive proposals of regions that are fed into the RPN. Anchors take 9 proposals per feature vector pixel, 3 sizes and 3 aspect ratios . In total you get 9 * H * W anchors* as input to the RPN, which the RPN will rescale to produce region proposals.
*Where H and W are the spacial dimensions of the output of the CNN backbone.
What is approximate joint training?
You combine the training of the RPN with the Fast RCNN. It’s approximate because you don’t backpropagate through the proposals (?).
What is non-approximate joint training?
This uses RoI pooling that allows you to backpropagte through the proposals. i.e. RoI align.
What is the 4 step alternate training?
What they use in this paper*.
- You get pretrained weights, say VGG, and you train your RPN through the whole backbone.
- You use the proposals made by your RPN to transfer-train a whole new pretrained VGG network that does the Fast RCNN part.
- You keep the network from part 2, and only keep the RPN specific layers from part 1, and you train the RPN network.
- You train the Fast RCNN layers only(?)
*I’m 99% sure I understood what they meant, but I may be wrong.
What are ablation experiments?
Experiments to check whether removing a layer or function has an effect on performance of the network.
What are cross-boundary anchor boxes and how are they dealt with?
Anchor boxes that cross the boundary of the input image; there are a lot. At train time, you just discard them. At test time, you clip them and use what you can.
How are overlapping RPN proposals dealt with?
Non-max suppression.
Lin et al “Feature Pyramid Networks for Object Detection” 2017
https://arxiv.org/pdf/1612.03144.pdf
What are image feature pyramids?
A pyramid of downsampled images, each of which goes through an RCNN and detects objects, this it to help with scale differences between the same class of object in the same image.
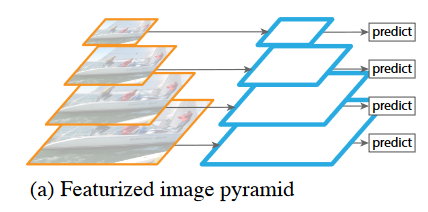
What is an issue with featurised image pyramids?
They’re slow.
What is the idea behind Feature Pyramid Networks (FPNs)?
When we build a CNN, it natually has a pyramidal shape, where high level, low semantic feature vectors are at the bottom, and low level, high semantic feature vectors are at the top, but both represent the same image.
We can apply (essentially) the same methods that we do to featurised image pyramids to our own images instead, and have lateral connections.
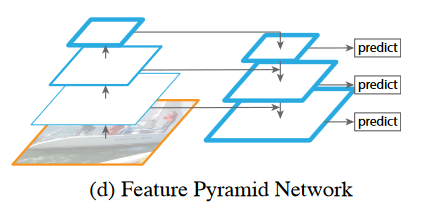
What is the technical implementation of the FPN?
This is a detail about upscaling the top down network and combining it with lateral connections from the bottom up network. See the image below.
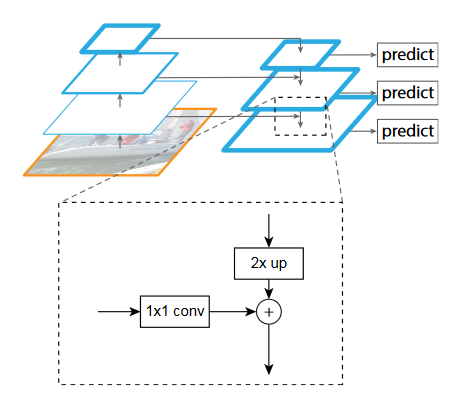
So we have lateral 1x1 conv operations to preserve HxW, but to decrease the channel dimension. We also have the top down connection which does nearest neighbour upsampling. We then add the two element-wise.
Past this there are details about how the RPN is altered from the original proposal by the Faster-RCNNs paper, but don’t seem relevant.
What can you say about the channel dimensions of the top-down pyramid?
All layers have the same number of channels.
Lin et al “Focal Loss for Dense Object Detection” 2017
What is the focal loss formula used in the paper? What is the aim behind using this loss?
The aim is to overrepresent underrepresented images.
Recall that cross entropy loss is
Where is the probability of the correct class.
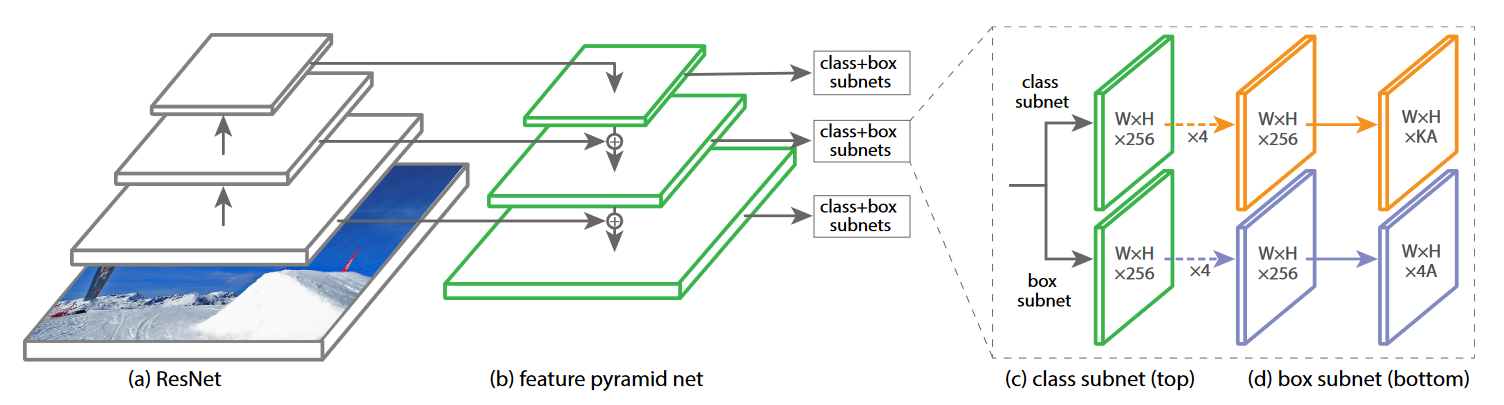
What is the RetinaNet architecture?
Feature pyramid network (FPN).
Then one 4 layer, 3x3 conv subnetwork for classification at each pyramid level, which outputs , where is the number of classes and is the number of anchors.
Also, after the FPN, theres a different 4 layer, 3x3 conv subnetwork for box regression, which has output dim .
Tian et al “FCOS: Fully Connected One-Stage Object Detection” 2019
What is the architecture?
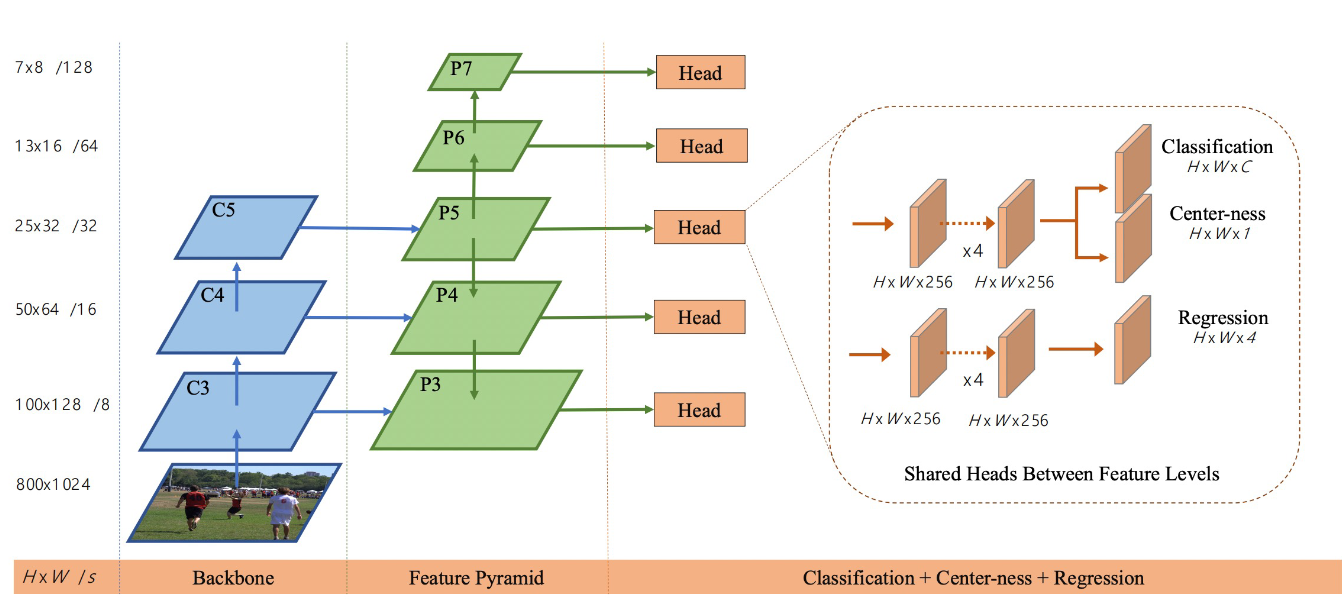
What notion behind FCOS?
Look at points in a deep feature space and decide if they’re in the bounding box, then predict the left, right, top bottom parametrisation of the boxes from that point. Also predict the centerness of each point in it’s bounding box.
What do you do at test time?
Multiply centerness by classification accuracy so that more centered pixels get the box.
How do you avoid the issue of one point overlapping in 2 objects?
Pick the object with the smaller area.
Lecture 15 - Image Segmentation
What are positive, negative and neutral region proposals?
Positive regions contain objects*.
Negative regions do not contain objects*.
Neurtral regions contain weird crops of the object, like just the face of a dog, when the whole body is present in the ground-truth.
*With some IoU threshold.
How does region proposal classification work for Faster R-CNN?
You run it twice, once throught the reigion proposal network and once for the head*.

*classification and bounding box perturbations.
What are 2 problems with RoI pooling?
- The region that is snapped to is not the region that is found by region proposals.
- We can’t backprop through it* since we don’t know what the original region would’ve been when looking at the snapped region.
*Not sure why lol.
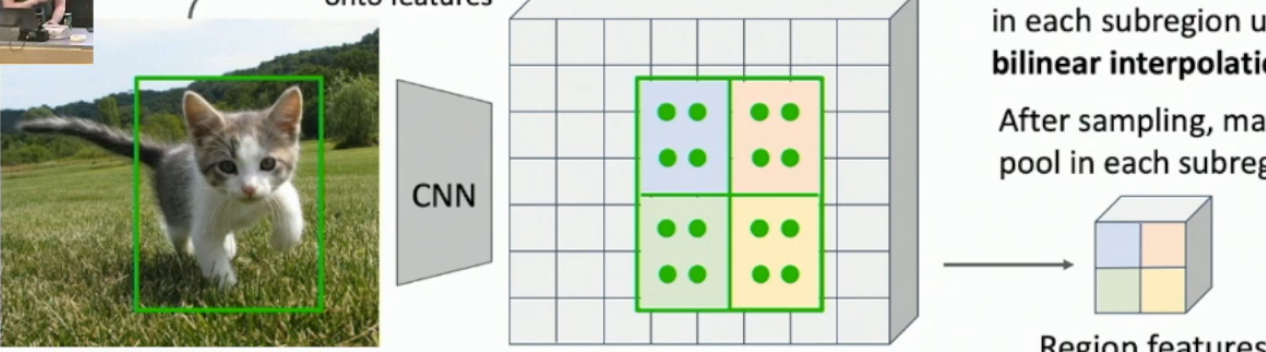
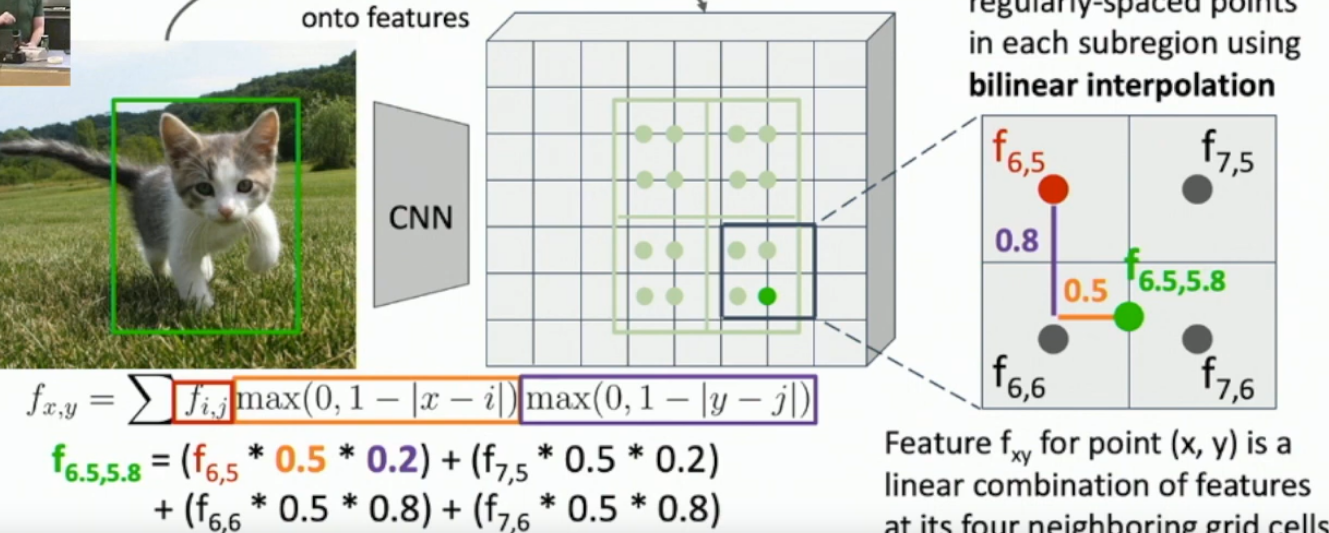
What is RoI Align? How does it address the issues with RoI pooling?
RoI Align is just taking a bilinear interpolation of a regular grid of points taken over a region proposal, and then max pooling it.
Each point - - is averaged in the following way
Where each ( are points in the feature vector representation. See the images below.
What is CornerNet?
Creating bounding boxes with an upper-left coordinate and a bottom-right coordinate*.
Now bounding boxes are found with upper-left and bottom-right coordinates, each of which has an embedding vector, and we find a upper-left+bottom-right pair by comparing embedding vectors.
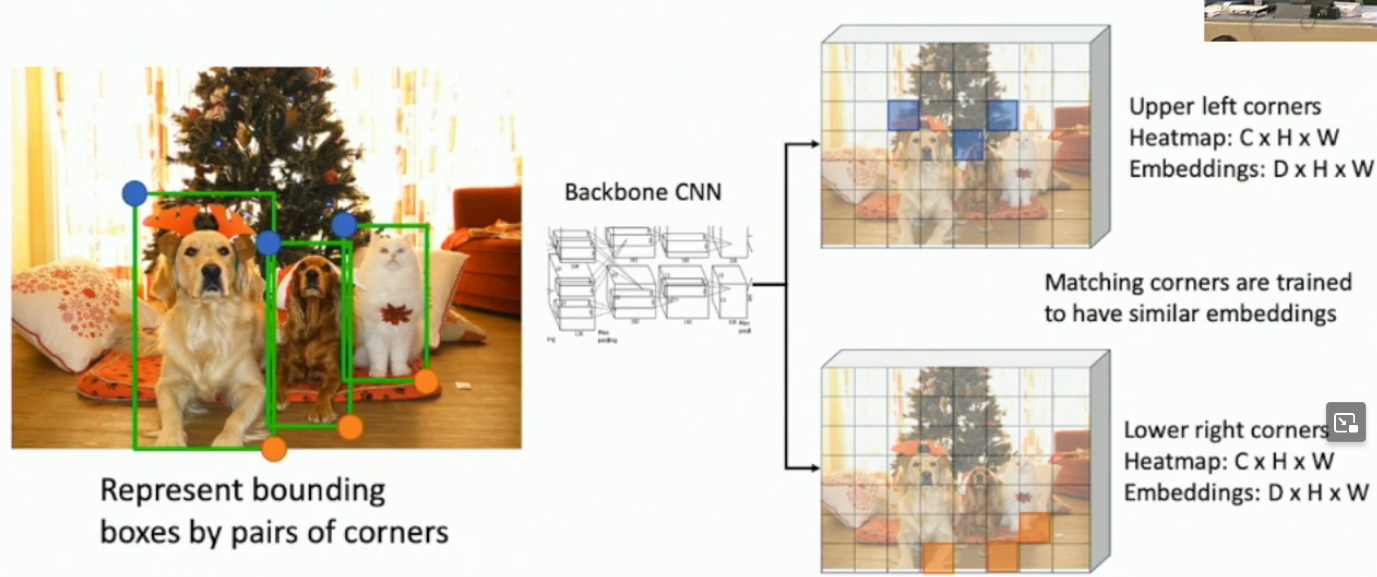
*Which differs from the typical (x,y,h,w) params.
What is semantic segmentation?
Segmenting an image into classifiable sections. Note it does not differentiate between 2 objects of the same type.

What is a fully convolutional network? How is it used in semantic segmentation?
Just 3x3, stride 1, pad 1 convolutional layers with a CxHxW output.
So the output is the same dimensionality as the input.
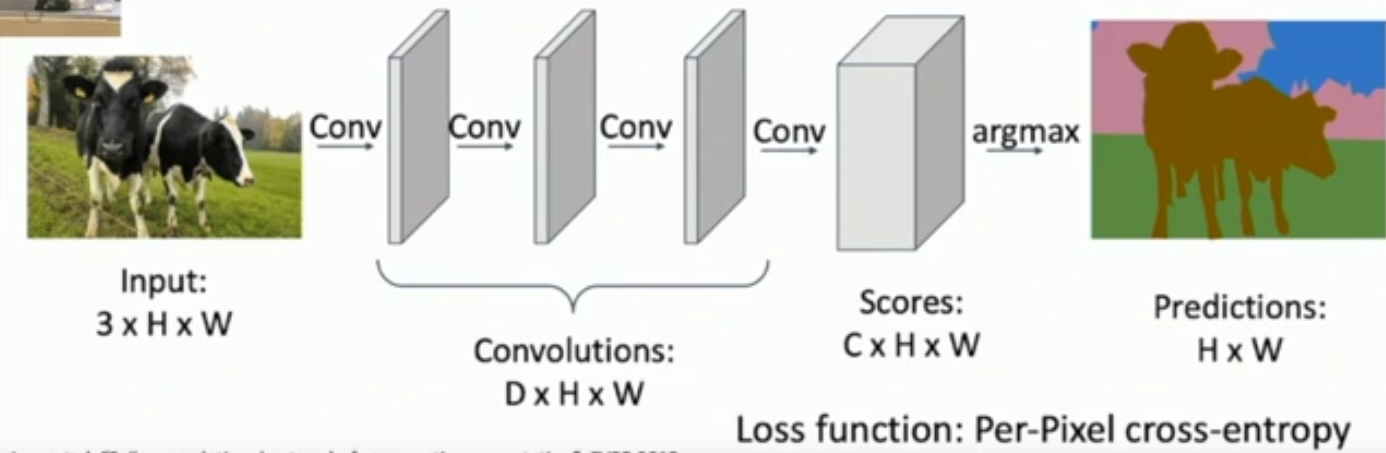
What are 2 problems with the fully convolutional approach to semantic segmentation? What is a solution to these issues?
- To get a large receptive field for effective segmentation you need a lot of layers. 1 + 2L is the receptive field for a network with L layers. Different for filters that aren’t 3x3.
- Computationally expensive to convolve repeatedly over high res images. Note ResNet has an aggressive downsampling stem.
Solution
Downsample and then upsample.
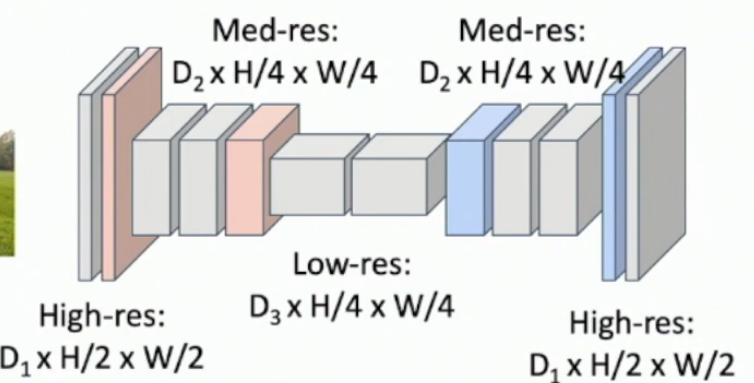
What is upsampling and what are 5 non-learnable methods for it?
Upsampling is increasing the height and width dimensions of a conv layer.
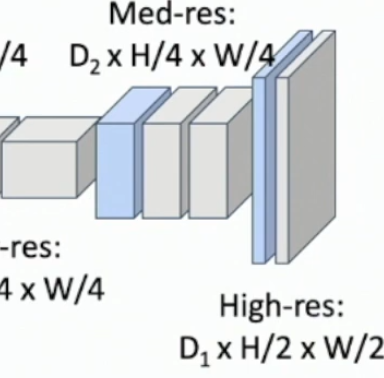
Non-learnable methods
(1) Nail-bed
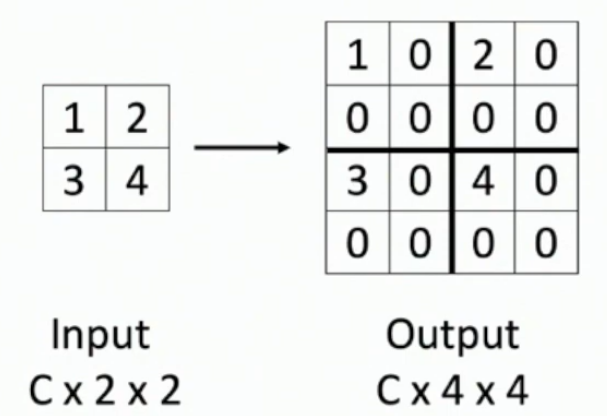
(2) Nearest Neighbours
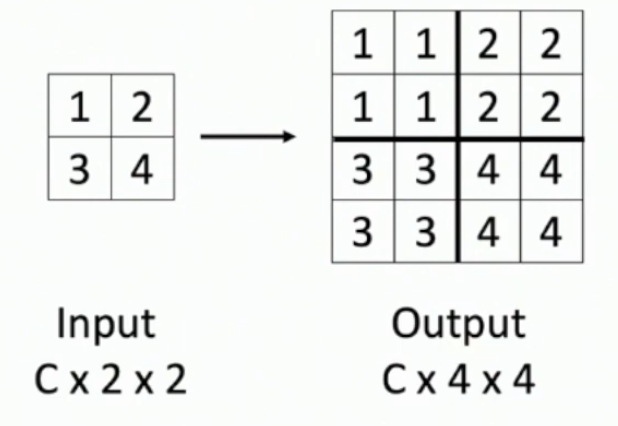
(3) Bilinear interpolation
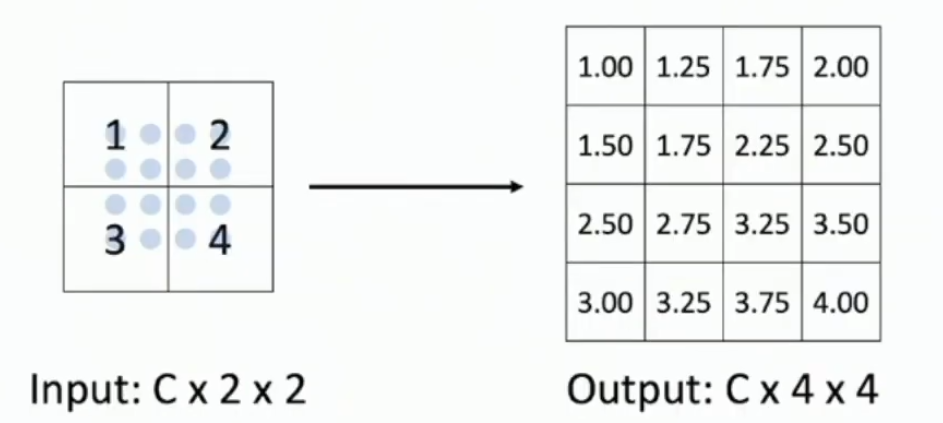
(4) Bicubic interpolation
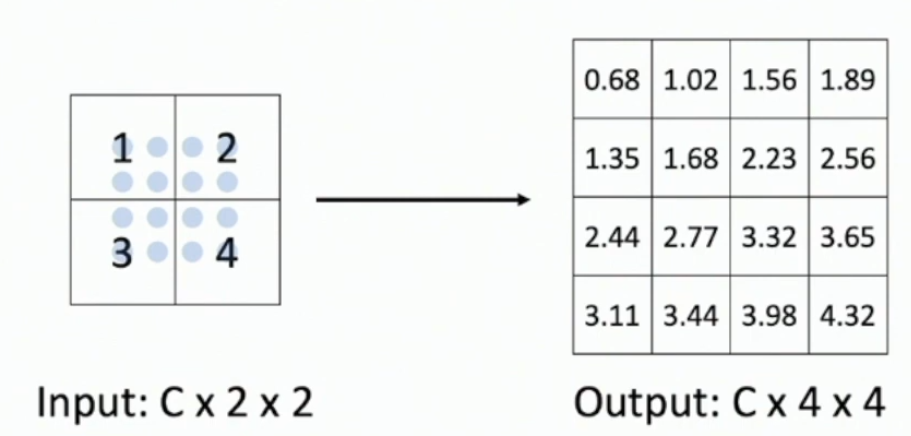
(5) max-unpooling
Nail-bed, but the chosen square is the one that was selected in the conjugate* desampling layer.
*Or similar, correpsonding, etc..
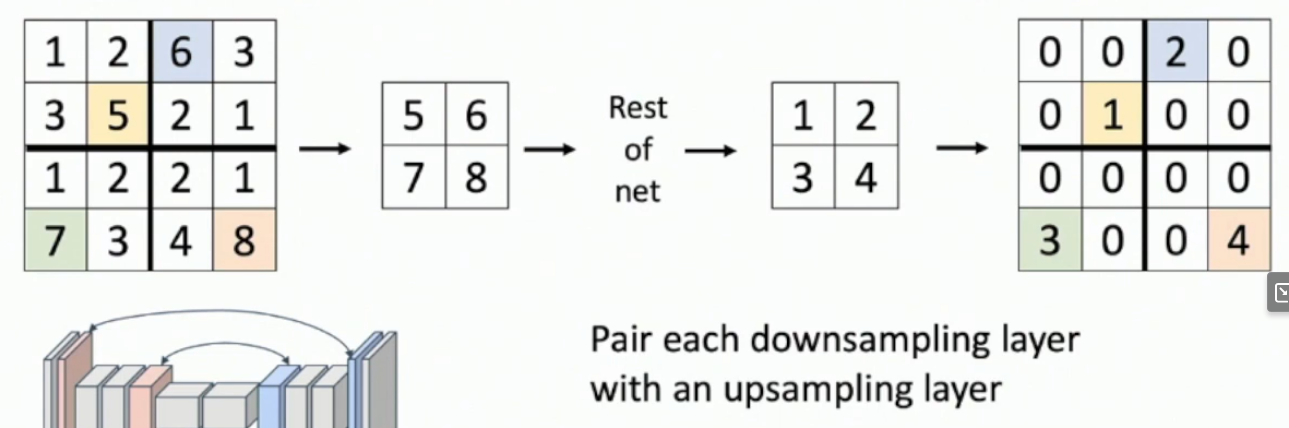
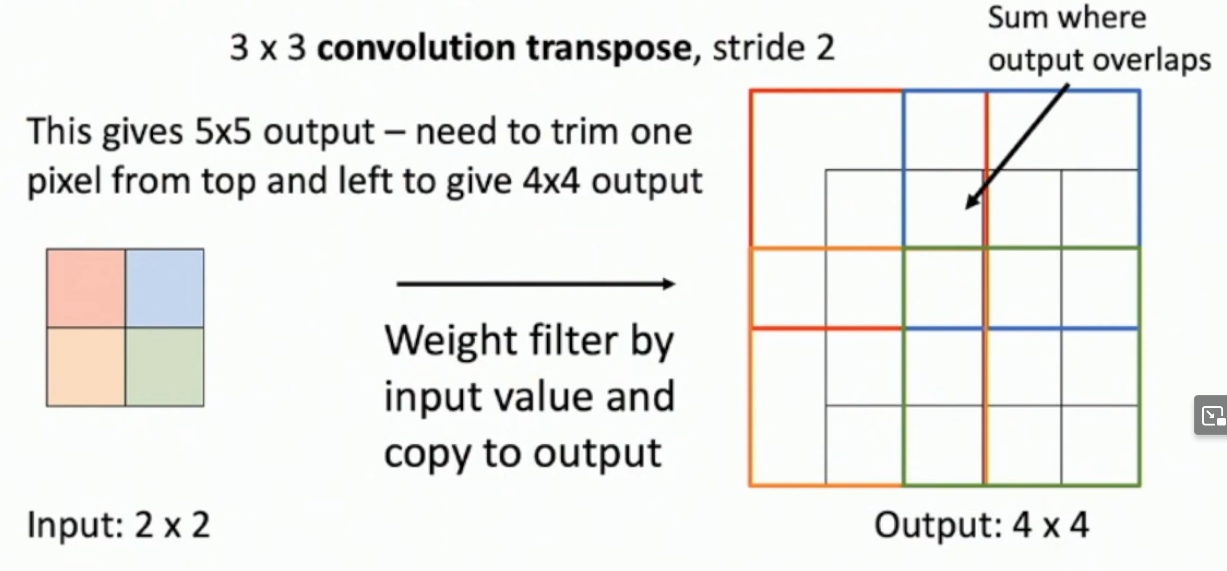
What is transposed convolution?
A learnable upsampling method where each cell in the input multiplies a filter and that filter helps to construct (a larger) output. Output size varies depending on desired output size and output stride.
What are Things and Stuff?
Things are identifiable singular objects, like cat, dog, car, building, etc..
Stuff is more-or-less homogenous textures, like grass, water, sky, etc..
This differentiation is commonly made in practice.
What is instance segmentation?
Object detection where you also segment each object.

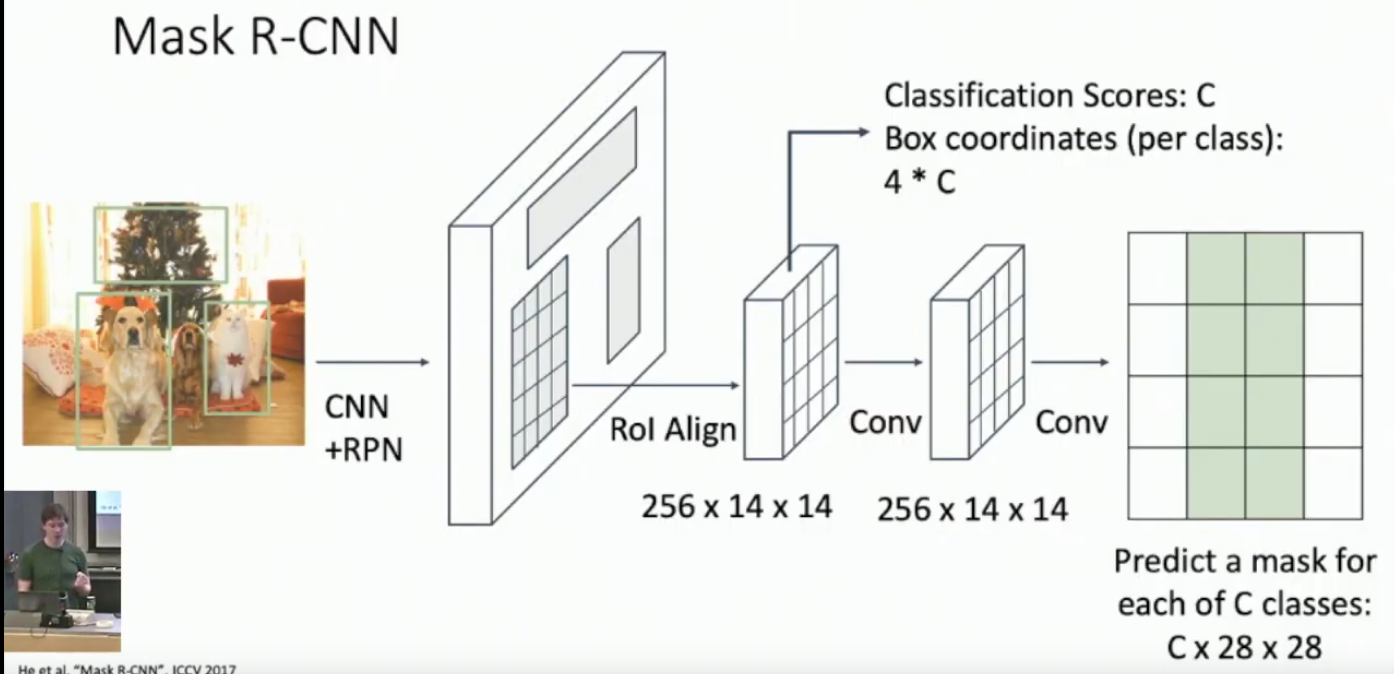
What is a mask R-CNN?
How to implement instance segmentation.
It’s an additional output alongside the box and classification. You segment the crop into foreground and background. Essentially predicting a mask that goes over the object and leaves out the background.
What is panoptic segmentation?
Instance segmentation + segment the background.
What is keypoint segmentation?
Finding details about segmented object, i.e. human gait/posture

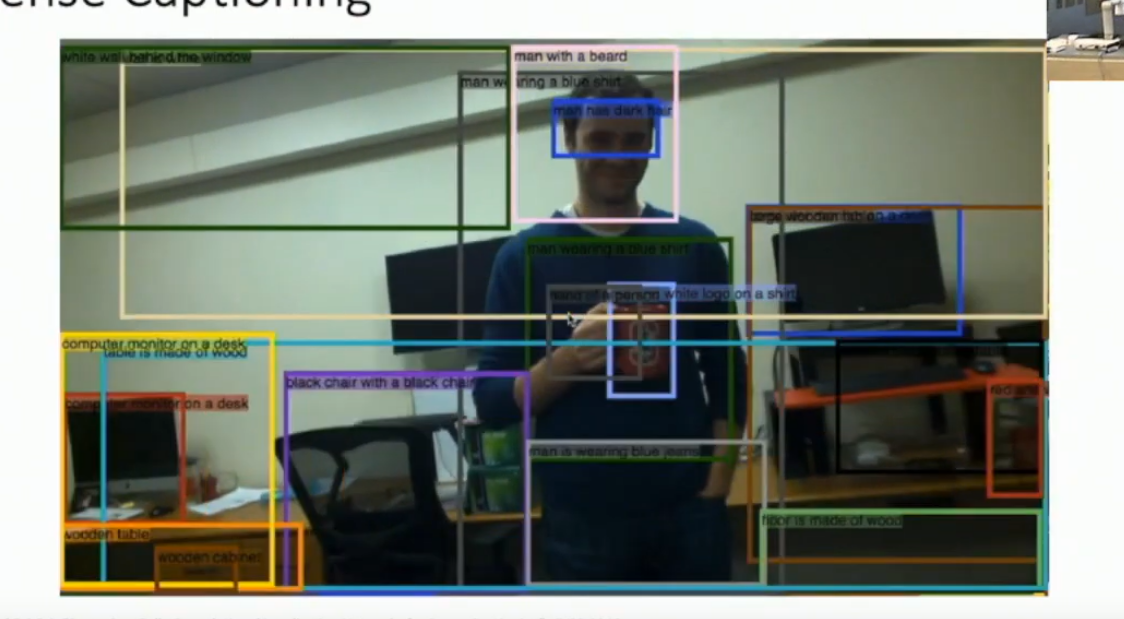
What is dense captioning?
Do Image-to-text captioning for each bounding box.
Lecture 16 - Recurrent Networks (RNNs)
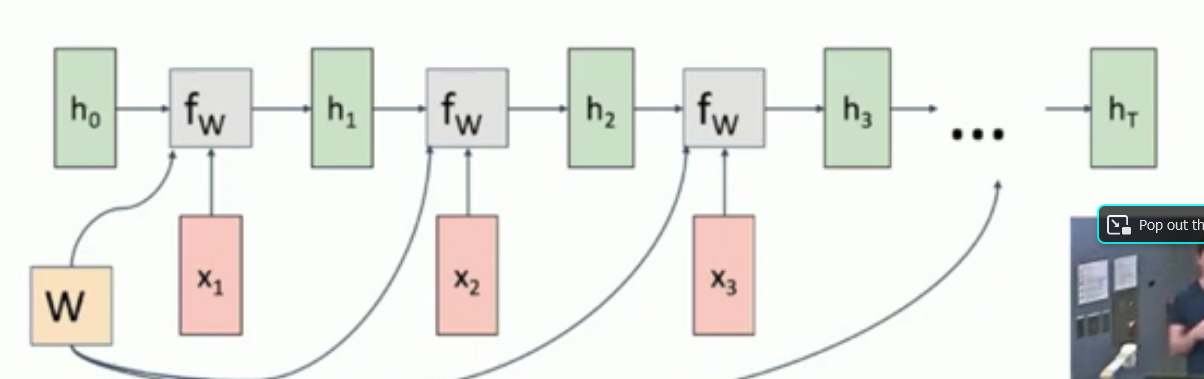
What is a vanilla/Elman RNN?
It is a neural network made up of repeated blocks of the following type.
You have a hidden state, an input and potentially an output.
Then, if it exists, we have
What is a common setting for initial hidden state?
Zeros.
How to make a sequence to sequence model?
Many to one, followed by one to many.
Essentially it allows for variable input, leading to variable output, like machine translation.
So you get the ouptut from a many to one RNN, which essentially encodes latent variables about your input text, then you pass that output into a one to many network, which generates text in a new language based on the latent variable vector.
Why would you use an embedding layer in an RNN?
If your input is one hot, like indexes of an alphabet, then the matrix multiply will just be the extraction of one column vector, which can be done much faster with simple indexing.
What is an issue with backpropagating through time? How can we address it?
You need to keep track of a lot of inputs, and hidden states, and if you have potentially infinite timesteps, this leads to a memory issue. Even if the sequence is ‘long’, it may be long enough to choke up you gpu memory.
To address this, you can use truncated backpropagation through time, which is just backproagating through every 10, or 100, or some power of 2* timesteps.
You miss out a bit of information, but it still works.
*lol
What features of the text that it’s reading might an RNN be learning?
A hidden state vector may have a lot of information in each element.
One element may say whether or not you’re in a quote by switching itself on(1) and off(-1), or if you near the end of a line by going gradually from -1 to 1(if you have a char limit per line of the text you’re reading). It may also notice whether you’re in a condition in some code text. See the example below for the quote-noticing-element.

How are RNNs made to be variable length?
The input is naturally variable length, but the output, for example in image captioning, may be started with a <START> token, and then the RNN can decide when to print an <END> token, which will stop the RNN from continuing forever.
I suppose there’s a possibility of the RNN going forever if it never decides to print the <END> token.
How is image captioning done?
You remove the last layer of a CNN trained on imagenet.
Then you have the new relation of
Where is the vector of the last layer of the CNN and is the weight matrix to be learnt. is added to each RNN block.
What are some causes for failure cases in image captioning?
Limited images in labels. Anyone standing next to a beach is though to have a surfboard for example. It works well on data it has seen, but people are weird and put all sort of random changes into any environment.

What problems occur with vanilla RNN backprop? How are these addressed?
Exploding gradients if matrix has it’s biggest singular value>1.
Vanishing gradients if matrix has it’s biggest singular value<1.
Could try setting the largest singular values to 1.
However, you could also do gradient clipping, which is getting the euclidiean norm of the gradient, and if it’s bigger than a threshold, then you divide each element in the gradient by threshold/norm. see the code below.
grad_norm = torch.sum(grad*grad) if grad_norm > threshold: grad *= (threshold/grad_norm)You could also just use an LSTM.
or just use an LSTM.
What is an LSTM?
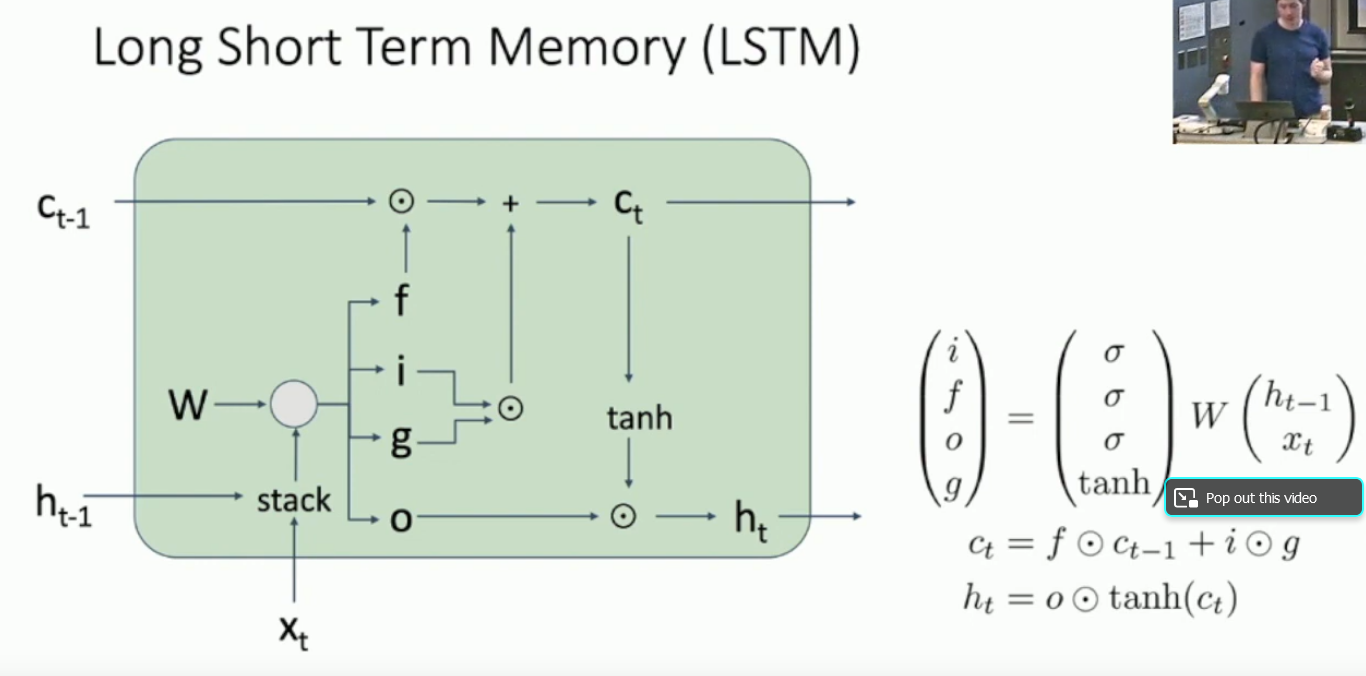
The main thing about an LSTM is that it maintains a cell state, which allows for easier backpropagation, since it essentially creates a highway for gradients along that top line.
Note that the stack step simply means stacking h and x into one vector.
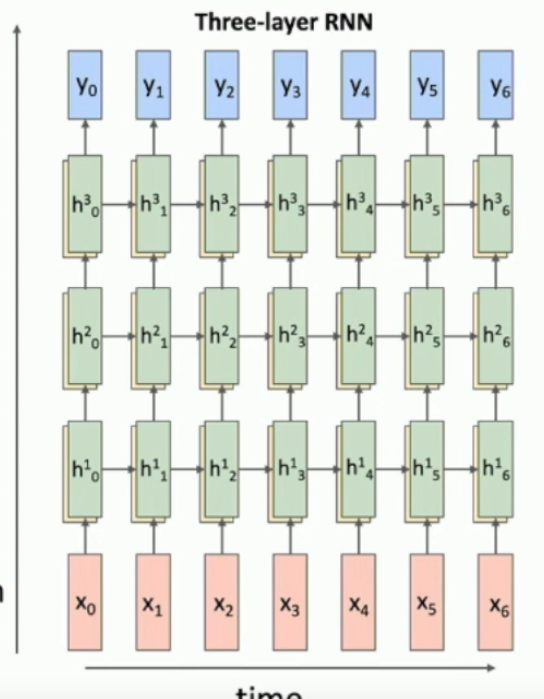
What are multilayer RNNs?
Just deep RNNs, but don’t use more than 5 layers bc you don’t need to.
Lecture 17 - Attention
What is sequence-to-sequence learning with attention?
You get the output from the encoder network.
for every hidden state in the encoder network, you apply an attention function , which is actually a network, whose values are learnt, we call the output .
Then we apply a softmax over the whole vector of outputs, to get a probability distribution.
Then get a weighted sum of each hidden state and each weight, to get a context vector of the same size as the hidden states.
Now the first input to the decoder network will be a <start> token, the context vector and the initial hidden state of the decoder network, which may be set to .
Then upon finding the first hidden state of the decoder network, , you feed do the same thing as you did with .
See the diagrams below for an illustration.
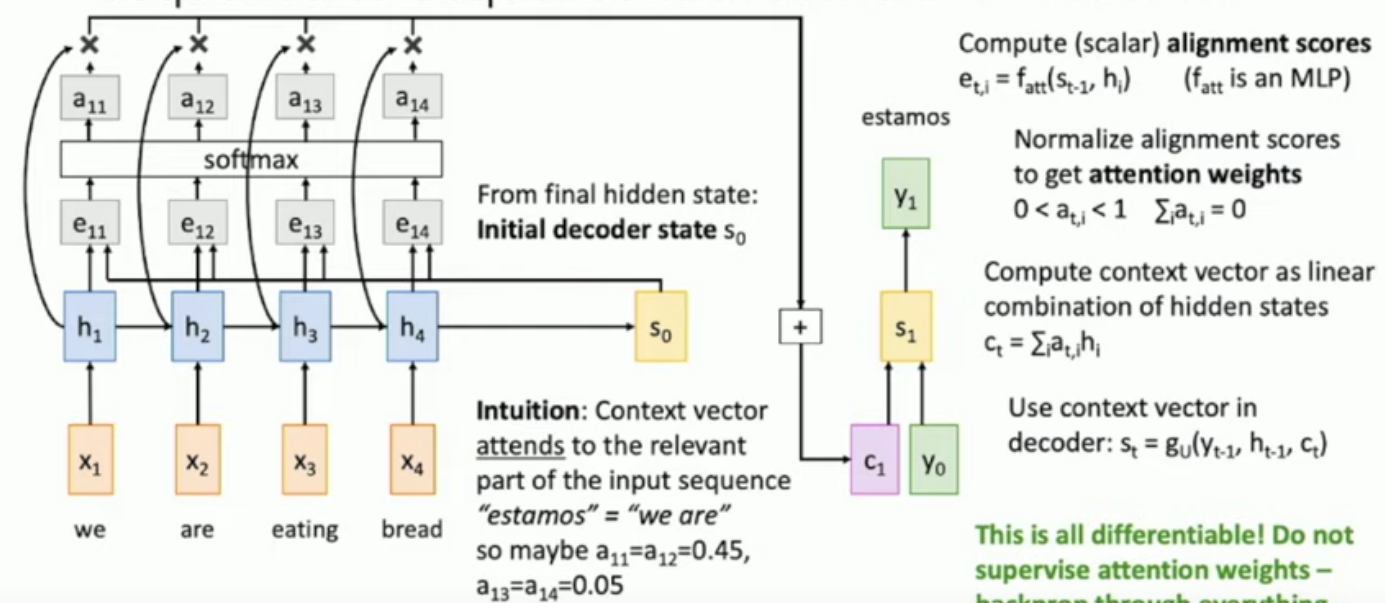
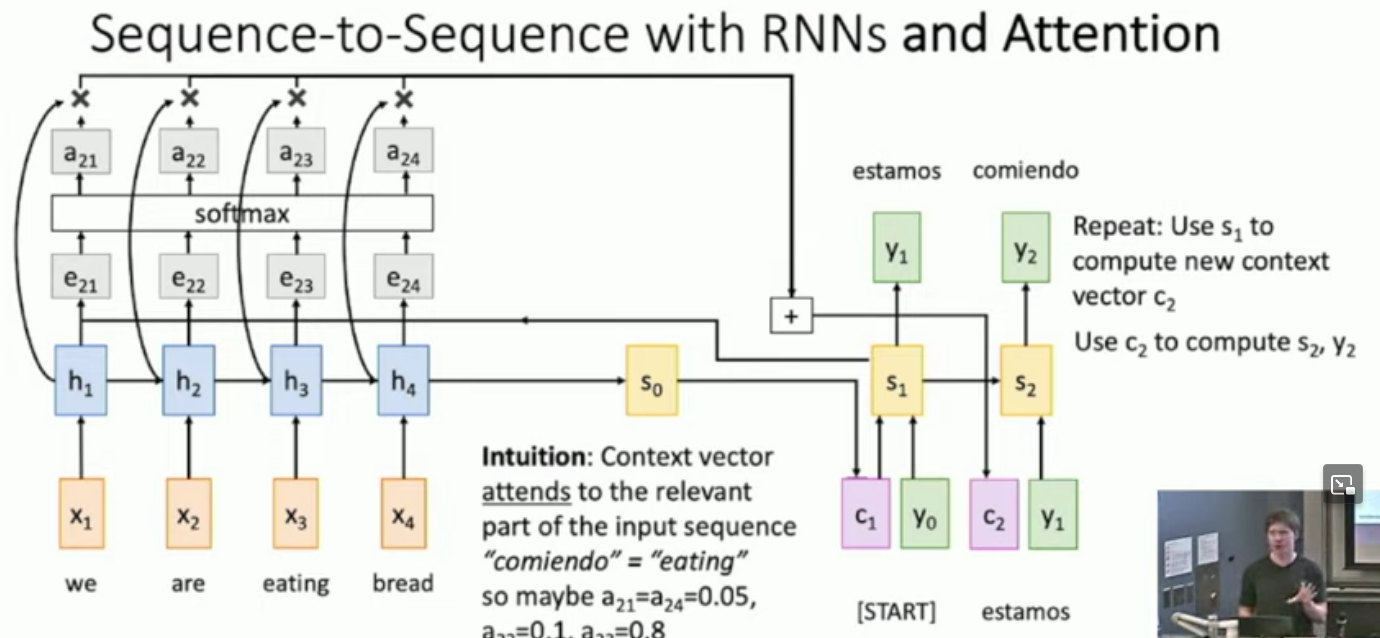
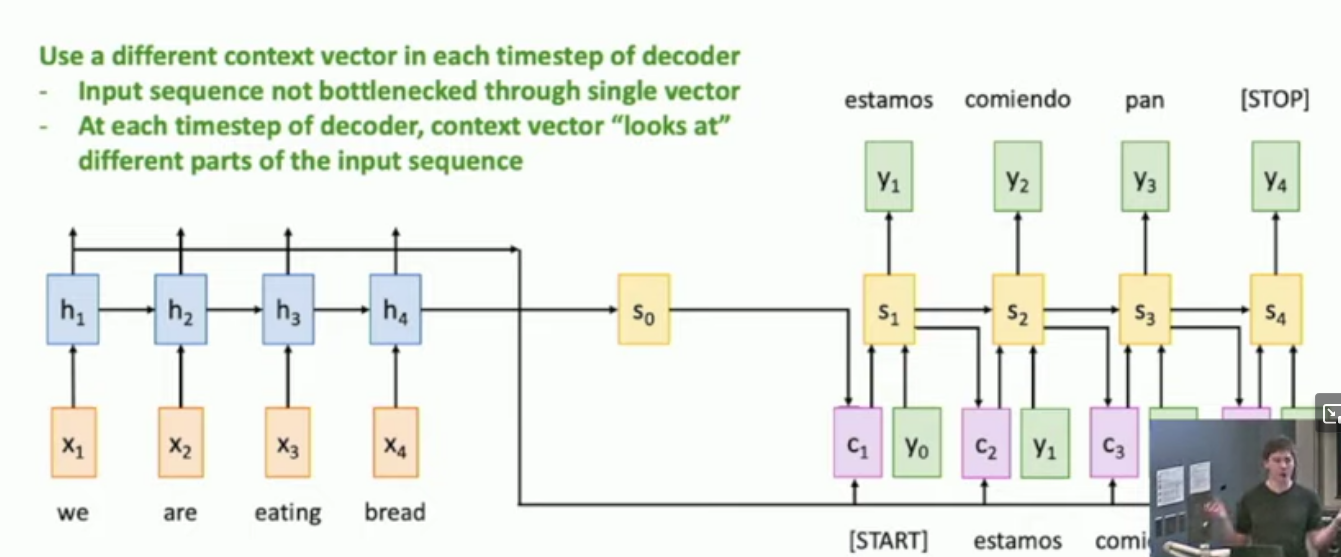
Don’t mind justin, he likes being in the corner.
What is the general structure of an attention layer?
You have an input vector, a query vector, a key vector and a value vector.
You combine these to get outputs.

What is a self-attention layer?
Instead of external query vectors, you multiply input by a query matrix to get query vectors, the rest is the same.

What does it mean for the self-attention layer to be permutation equivariant? How can we make it permutation variant?
The order of input vectors doesn’t matter. To make it matter, we can attach a little variable to each that stores information about it’s location.
What is masked self-attention? when might it be used?
Set the left upper triangular part of a matrix to 0s, by setting the un-softmaxed outputs to -infinity. This is so that when processing a sentence, you only process what you’ve seen so far, not the entire sentence.
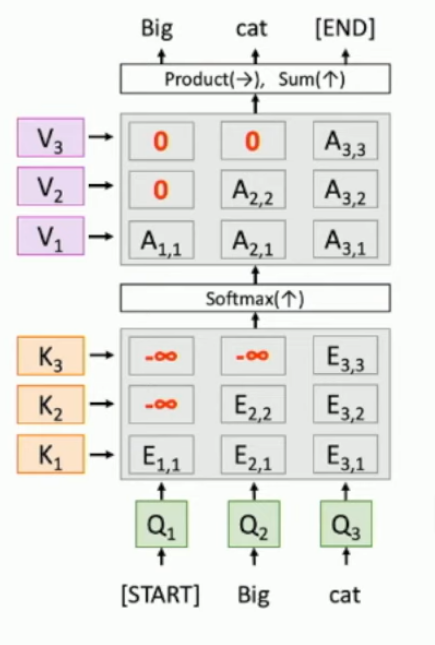
What is a multiheaded self-attention layer?
Say you have input vectors . You can split each input vector into chunks*. Upon splitting, you can send each collection of chunks into it’s own self-attention layer with a total of heads. in the end you concatenate all of the pieces back together.
Note, that each self-attention head will still have inputs, they’ll just be smaller by a factor of .
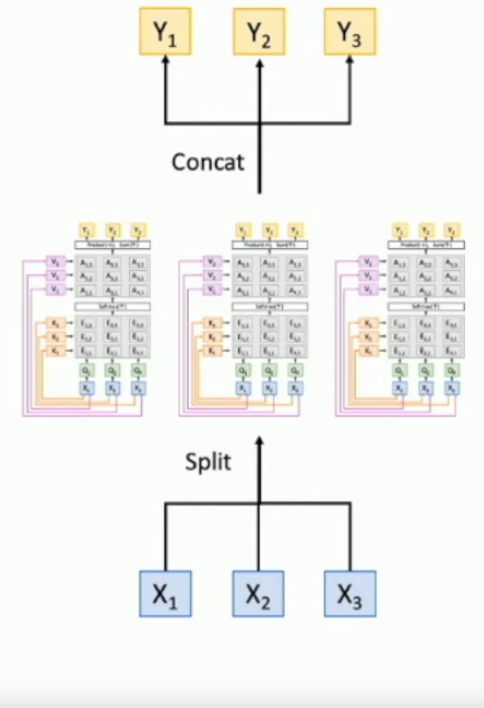
*If the integers work out
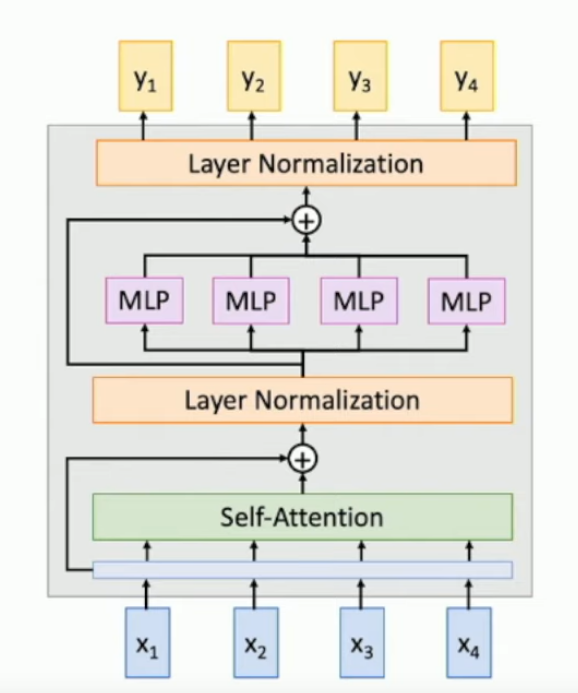
What is a transformer block?
- A self attention layer.
- Followed by a residual sum.
- Followed by a Layer normalisation.
- Followed by an MLP for each input.
- Followed by a residual sum from just after step 3.
- Followed by another Layer normalisation.
- That’s the output.
See the diagram below.
Lecture 18 - Vision Transformers (slides only)
What are 4 ways we can incorporate attention into our models?
- Inbetween layers of our CNN; our network is still a CNN.
- convolutions are actually just self attention modules; not much better performance.
- Put our image through a transformer; STUPID HUGE attention matrix.
- Use a ViT: split up image and then put it through a transformer.
What is ViT?
- Split up your image.
- Linearise the images to vectors of size
- Add positional embedding vector.
- Feed this set of vectors through a transformer.
- Have an additional learned vector (classification token)
- Get dimensional output vector.
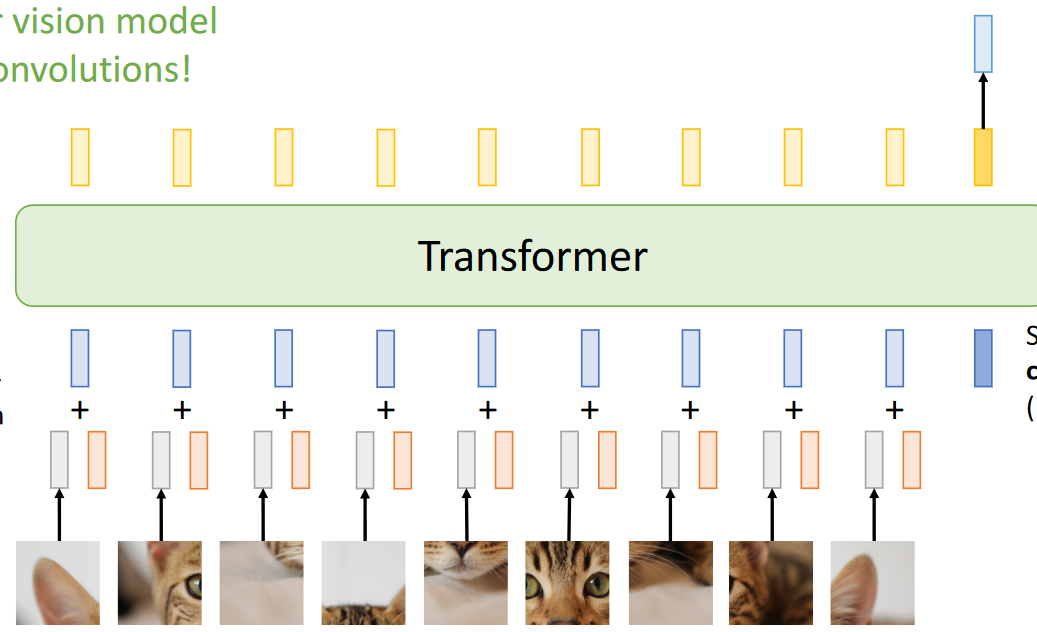
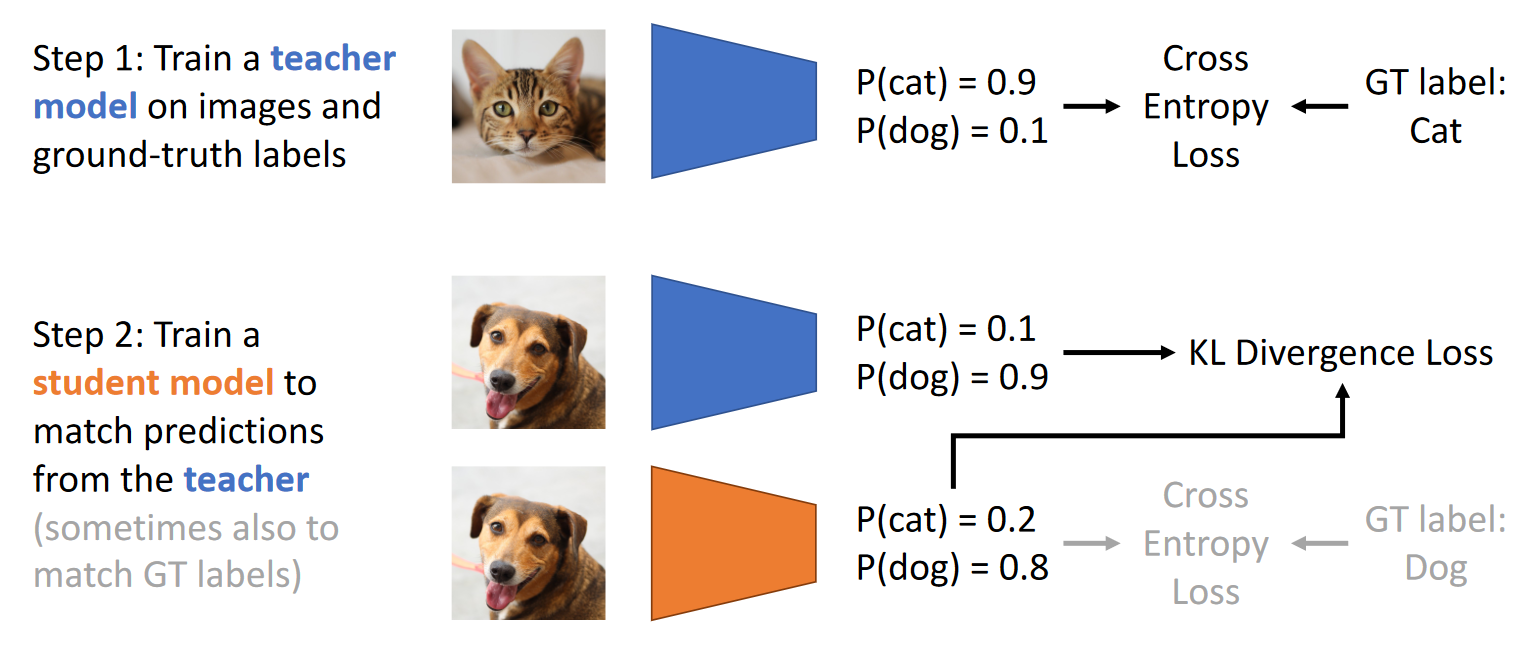
What is distilled ViT?
Train a parent CNN the usual way.
Train a student ViT to copy the output of the parent CNN and also the GT labels.
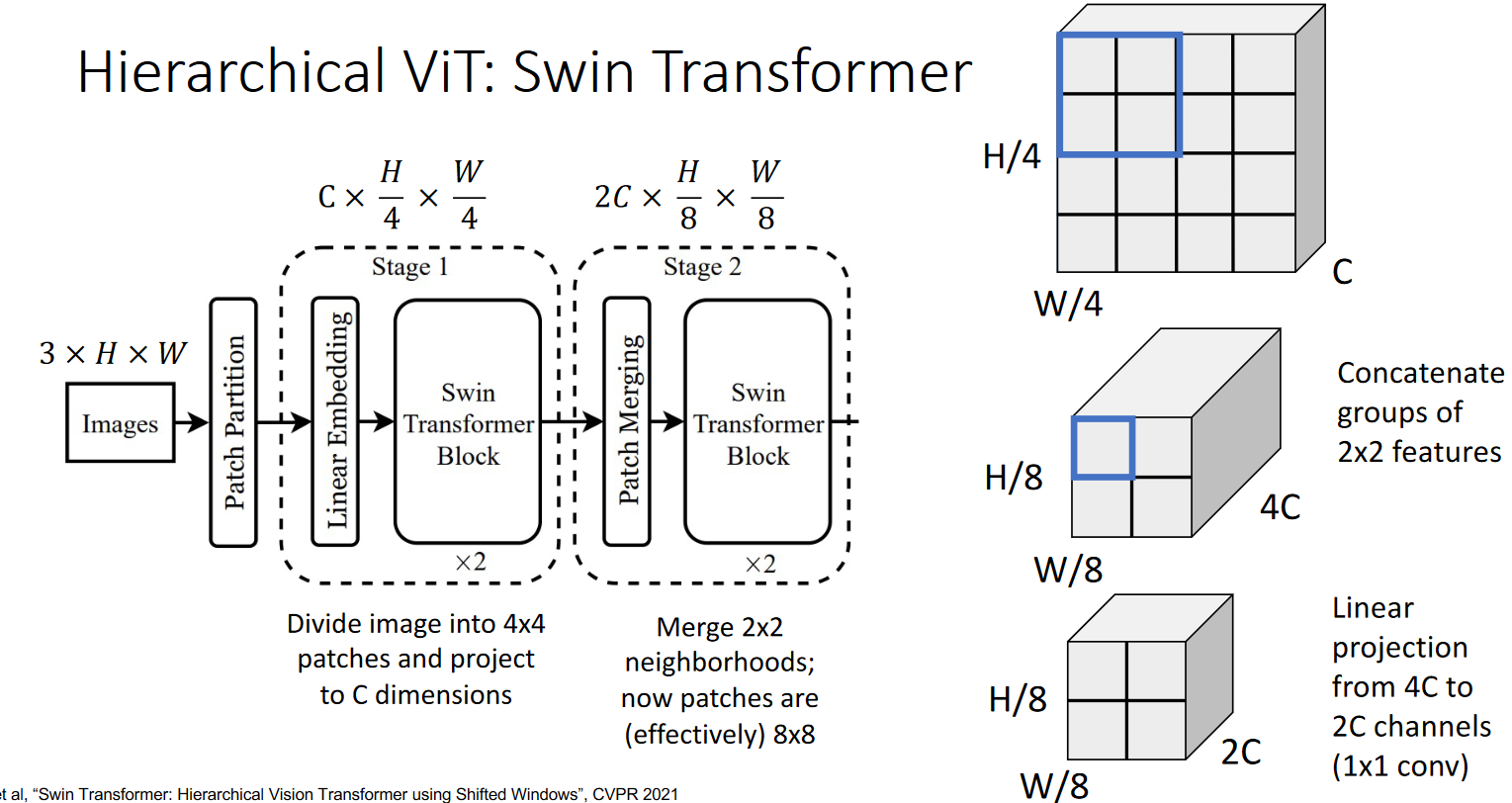
What is a Swin transformer?
Basically it downsamples a transformer network to make it hierarchical like a CNN.
Gets the output feature tensor, splits it up and stacks it on the channel dimension, then feeds that through a 1x1 conv to decrease channel size.
What is window attention?
The attention matrix for a full image is , which can be huge.
The aim is to decrease the size* that needs to go through the transformer by splitting up the image into chunks of size . So now each attention matrix has elements, and there are such chunks.
So in total there are now elements over all attention matrices.

*Of the attention matrix
What is an problem with window attention and how is it solved?
You don’t get communication between windows. This is solved by having different splittings before downsampling.

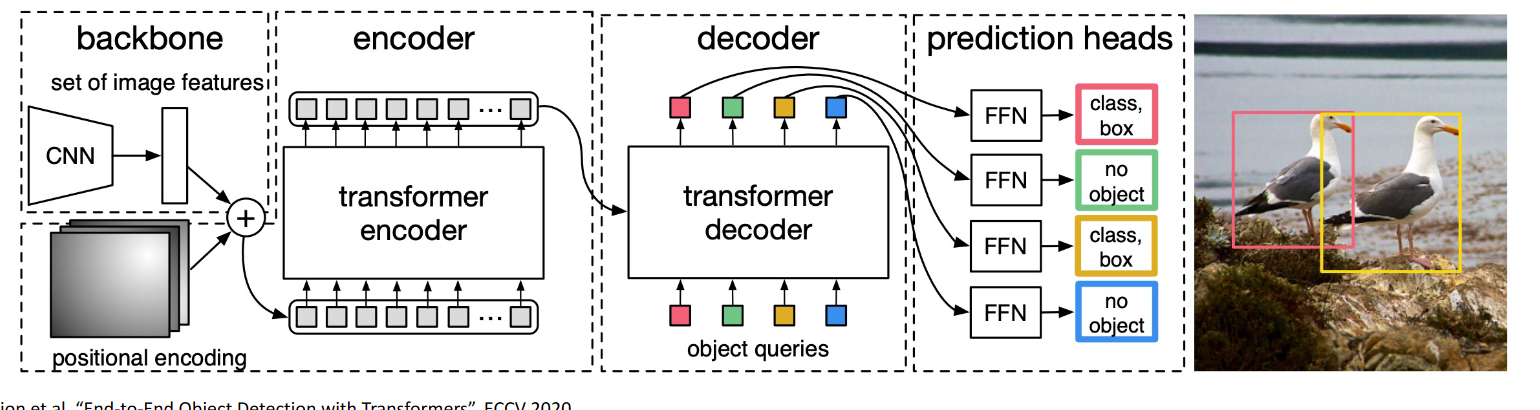
What is the architecture for object detection with transformers? (rough picture)
- Run through a CNN backbone to get a feature map.
- Add positional embeddings.
- Run through a self-attention transformer (encoder)
- Run that through another, attention transformer (decoder)
- Run decoded outputs through an object classifier+box-regressor.
What is a pro of using transformer based models for image tasks?
They’re faster. Similar performance.
Lecture 19 - Generative Models I
What is a discriminative model?
Like the classification CNNs we’ve seen so far. .
What is a generative model?
A probability distribution of inputs, likely input have high probability. So sending in noisy trash will have a low score, but a picture of a dog will have a higher score.
What is a conditional generative model?
Gets the probability distribution of an image, given a label. So if you have label “dog”, images of dogs will have a higher probability than pictures of cats, even though both pictures may occur equally frequently in the dataset.
What are explicit and implicit generative models?
Implicit models contain autoregressive models and VAEs. Explicit models contain GANs.
Other than that I don’t know the distinction.
What is the general form of an explicit density estimation model?
Given a dataset , we want to maximise where are our parameters. We assume is independent to . We want to maximise
Which is equivalent to
What is an autoregressive model?
It’s like an RNN.
What is a PixelRNN? What is an issue with these?
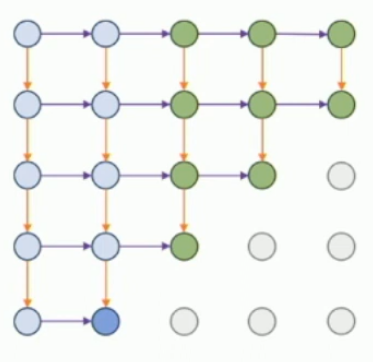
Can’t parallelize it - takes a long time to train/test.
What is PixelCNN? (See Salimans et al 2017)
Meant to be like a PixelRNN but with a CNN receptive field intuition. Not sure about implementation details, see Salimans et al 2017 paper for details.
What is the probabilistic difference between Variational Auto Encoders (VAEs) and autoregressive models?
VAEs have an intractable probability density so we can’t compute them exactly/optimise them perfectly; they’re actually a lower bound for a what the probability for an input is.
What is the probabilistic interpretation of VAEs?
Basically, you’re given latent vectors , that produce all via a decoder network.
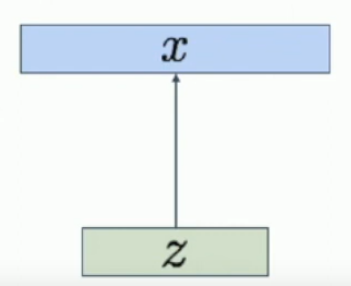
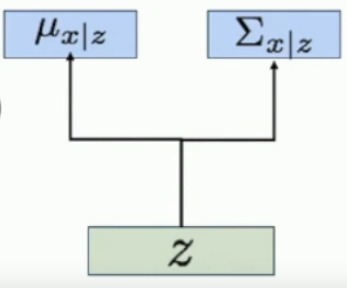
But we want a probabilistic interpretation, so what the decoder network does is generate a mean and variance for each pixel; given a latent vector input .
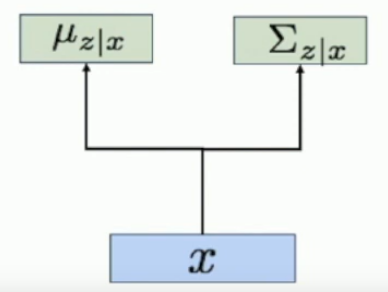
Now we want to find . We end up using Bayes rule, because marginalizing over is hard. So
and the hard part on the right hand side is the denominator so we approximate it with an encoder network .
Then we follow a few calculations to get lower bound VAE probability.
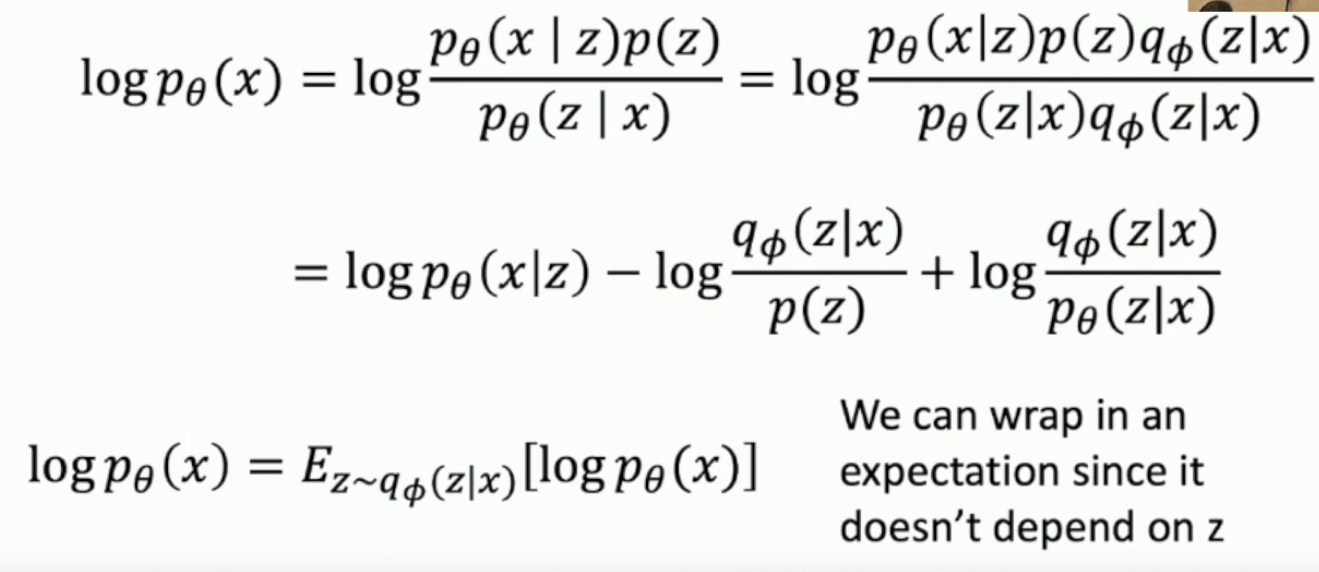

We get rid of the last KL divergence because it’s hard, which why we get that VAEs are a lower bound:
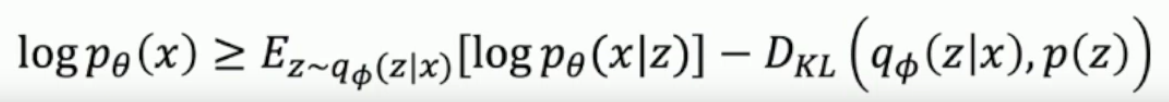
*Assuming that all pixels are independent which is not true unless you’re looking at pure noise.
Lecture 20 - Generative Models II
What is an autoregressive model?
Given a sequence of inputs, it predicts the next token.
How do you generate probability distributinos from a neural network with VAEs?
You output a set of means, and a set of corresponding variances for those means. It’s assumed that all variables are independent, so the covariance matrix is diagonal, i.e. number-of-means = number-of-SDs.
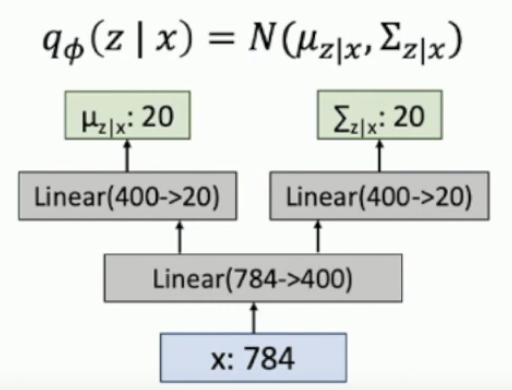
The same is true of the decoder network, except the input is 20 and the output is 784.
How do you train a VAE?
You need to maximise the lower bound
The second term can be expressed in closed form. The first term is found from the decoder, with inputs being samples from .
What are tradeoffs between autoregressive and VAE models?
Autoregressive:
+More detailed images.
+Directly maximise p(data)
-Slow
-No Latent codes
VAEs:
-Maximise lower bound
-Generated images are blurry
+Fast
+Useful Latent codes
How could you combine VAEs and autoregressive models?
VQ-VAEs.
Run it through an encoder network, then run the autoregressor through the latent codes, then run that through a decoder network.
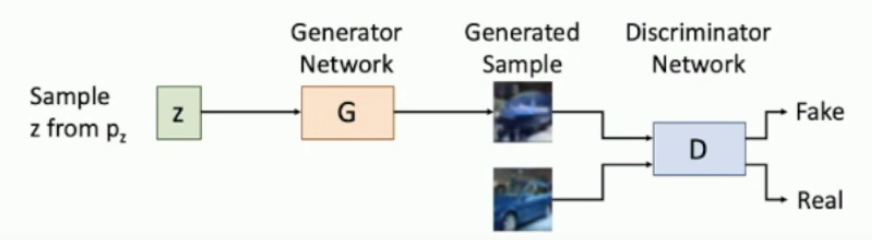
What are Generative Adversarial Networks (GANs)?
You sample , you run that through a decoder, now known as a generator, to get , which makes an image for you. Then you run that through a discriminator which is meant to tell if the image is fake or real. It also get’s real inputs , to train itself on real data.
We want, in the long run, . Which suggests that fake images are similiar to real images, and hence our sampling from the generator is almost equivalent to sampling from real data. Technically . Where
is another type of divergence, similar to .
See the image below for guidance.
How do you train a GAN?
The loss function is a minimax,
Since training is very slow for the second term, see below, we usually use a different formula, but this illustrates the meaning.
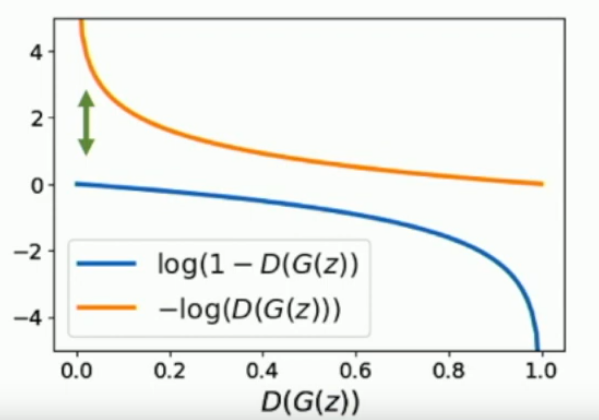
As you can see, gradients are tiny if we use the original discriminator loss for fake data.
What are some caveats to GANs?
- It isn’t clear that a neural network can produce a probability distribution , that has 0 divergence withe the ground truth probability distribution .
- Doesn’t suggest whether the network will converge to an optimal solution or not.
What is conditional batch normalisation? How is it related to conditional GANs?
Have different scale and shift parameters for each label, this allows for conditional (class-specific) GANs.
Lecture 21 - Visualising and Understanding
What are 2 ways of visualising/understanding weights in a CNN?
There are more that 2, however:
- We can look at first layer learnt filters and see what they look for, i.e. edges, colours, dots, patterns.
- We can look at the second to last fully connected layer, and do k nearest neigbours there to find similar images.
How can you visualise a CNN by looking at hidden layer convolutional activations?
The activation at a layer may signify the network identifying a specific feature, such as ‘person sitting’.
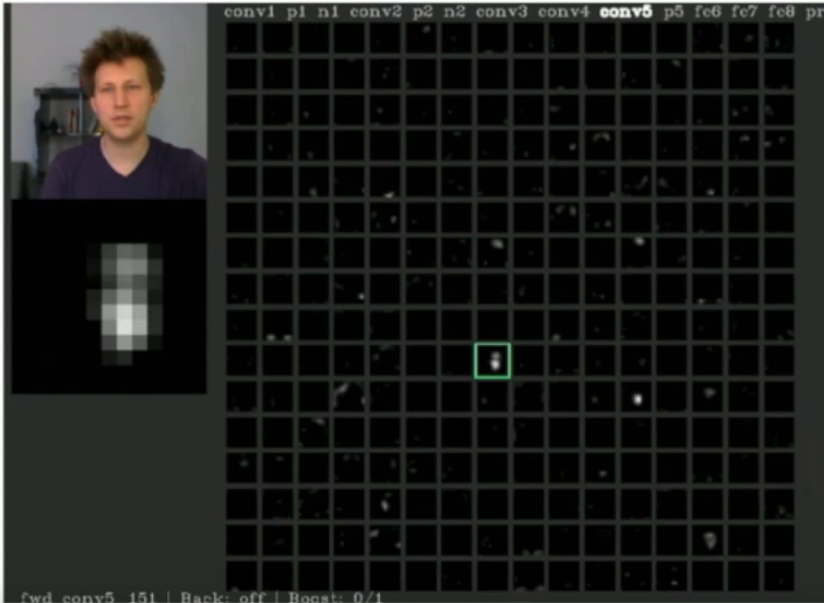
What are 2 ways of seeing which pixels (in the input image) are relevant for a correct classification (of that image)? - Saliency
- You could occlude the image systematically to produce many occluded images, and see which occlusions most affect the network’s ability to identify the image.

- Get the gradient of the correct class score with respect to the input.
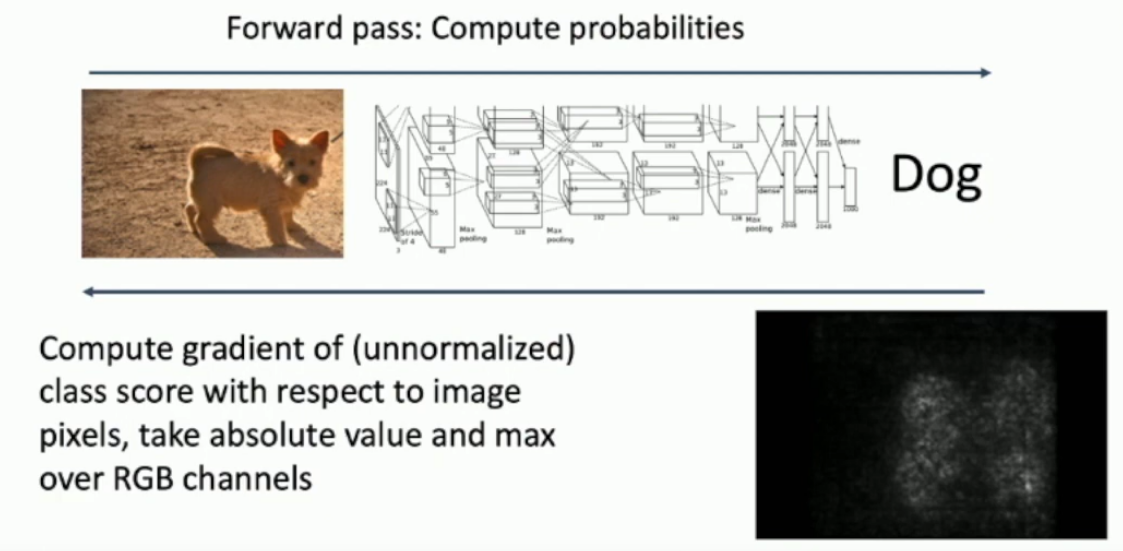
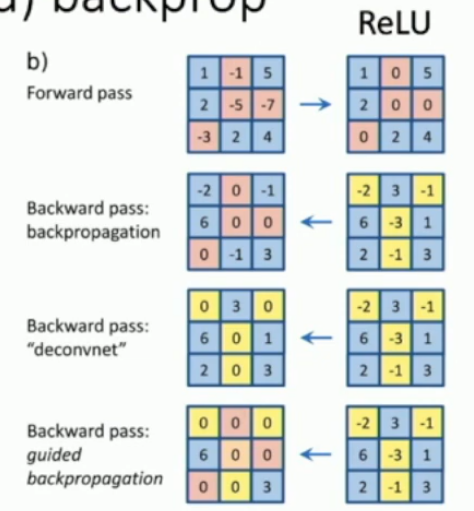
What is guided backprop?
Guided backprop is used when trying to identify relevant features for classification.
Its a weird form of backprop involving relu, where negative gradients are set to 0, and (as usual) the gradients of negative output values are set to 0. Apparently it makes images come out nicer when you backpropagate a class.
Was is gradient ascent?
Generating a synthetic image that maximally activates a neuron.
So you choose the activation of a neuron, and set it to maximal* activation, then backprop through that and see what image you get.
You also need to add a natural image regularizer term so that the output looks nicer.
Concretely,
- You start with a random input, could be noise, or zeros.
- You feed the network forward and get to the neuron you’re interested in.
- Then you backpropagate with to find gradient of that neuron’s activation wrt the image, and then update the image in the direction that increases that neuron’s activation.
- Repeat 2 & 3
Gets you images like this:

*or very large
What is an adversarial example?
- We have an image of an elephant and the network strongly predicts elephant.
- We purturb that image slightly in the direction of koala.
- The purturbed image still looks very much like an elephant.
- The network strongly predicts for the purturbed image.
- The purturbed image is called an adversarial example.
See the examples below

What is feature inversion?
You get to a feature space, say layer 5 in your network, and save it. Then you want to generate a new image, which creates the same feature space at layer 5. The deeper you do, the more the image diverges, though structure is maintained.
A natural image regulariser is added, see the math below.


What did deep dream do?
It seeks to amplify detected features.
You get to a feature space, say layer 5 in your network, and then the activated output of that space becomes is set as the upstream gradient. You then backpropagate from there and get your new image. The deeper you go, the weirder the image gets.

What is a Gram matrix?
An un-normalised covariance matrix between each channel slice for a CNN layer (is in ).
What do a Gram matrix tell us?
Which features activate together, and hence are related.
It ends up telling us which features co-occur without any relationship to their spacial value in the image.
How are Gram matrices used for texture synthesis?
Start with a random, or zeros matrix and repeat the following process.
- Get gram matrices for each layer of original CNN with an example image to create a texture from, i.e. some rocks.
- Run your zero/random matrix through the same CNN and calculate it’s Gram matrices.
- Compare the gram matrices and get losses.
- Back propagate to find the derivative of loss wrt the zero/random image.
- Update the zero/random image.
- Continue with updated image.
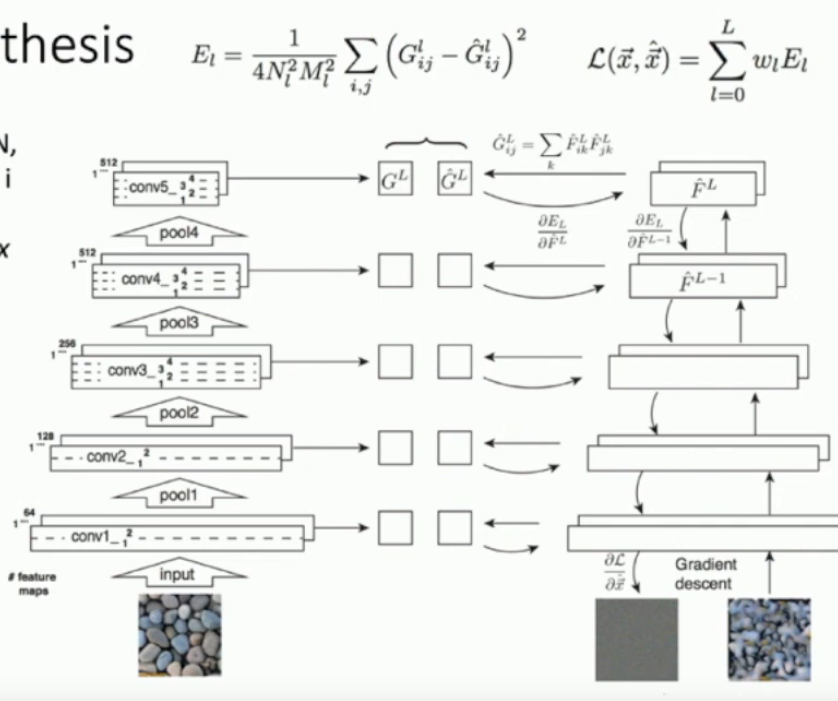
It works better the deeper you go with the layers.

What is neural style transfer?
A combination of feature inversion and texture synthesis.
We:
- Match the features of one image (structure image - something we can take a picture of)
- Match the gram matrices of another image (style image - A style we want to recreate, i.e. Van Gogh)
Done through gradient ascent through a pretrained network.
What is cool and bad about neural style transfer?
Cool: We can make very interesting images, like girl with the pearl earring in the style of Van Gogh.
Bad: Takes a lot of compute; expensive.
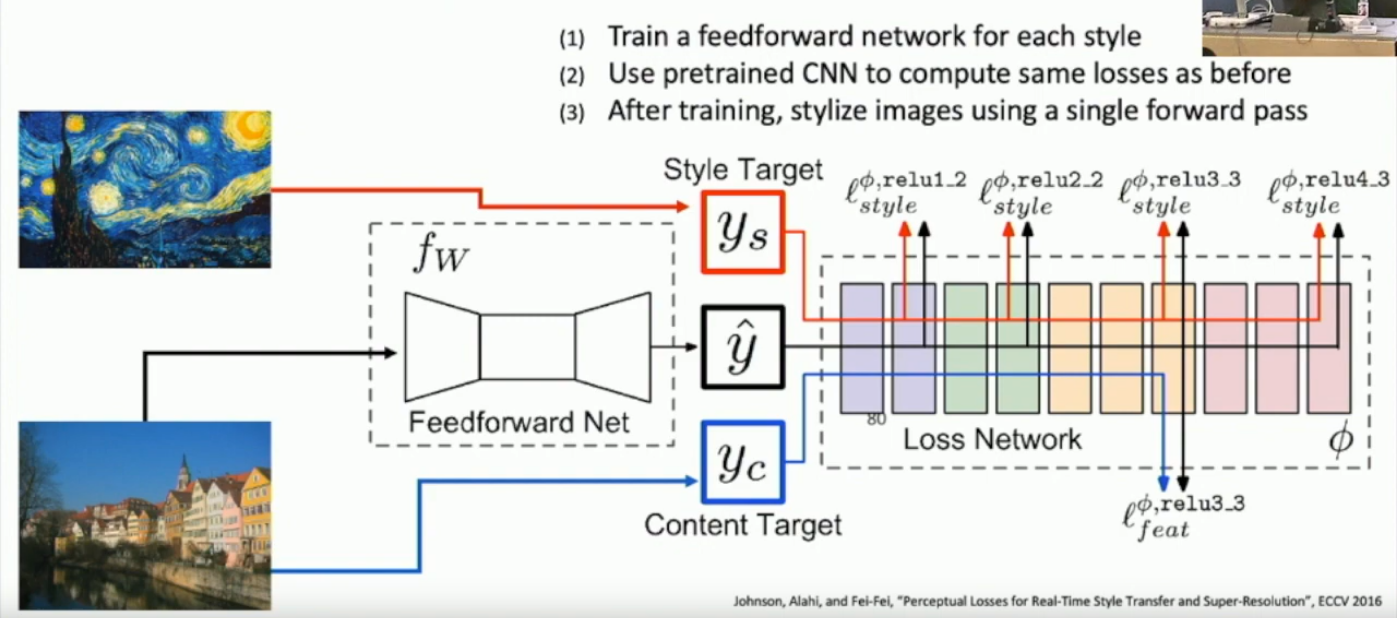
What is fast neural style transfer?
A network that learns how to apply styles to images.
Pro: fast runtime, especially when compared to initial neural style transfer.
See the diagram below for how it works. You have a whole loss network.
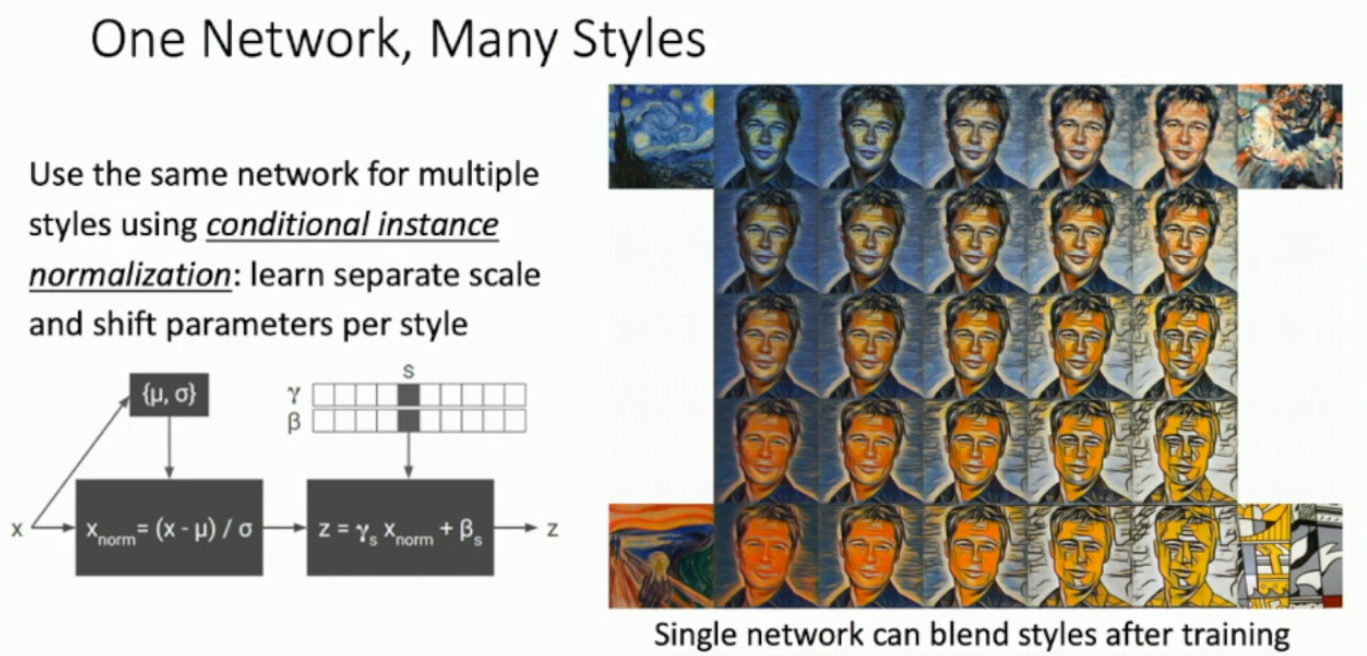
What is conditional instance normalisation?
Fast neural style transfer networks can only learn 1 style, using conditional instance normalisation we can learn many.
A normalisation technique that has different learnable and parameters for each style.
So if you want style A, you use one pair, for style B you have another pair.
You can also mix the styles for interesting results:
Recall instance normalisation:
Lecture 22 - Self-Supervised Learning (slides only)
What is self supervised learning? Why use it?
Basically just unsupervised learning.
Labelling data is expensive for good datasets.
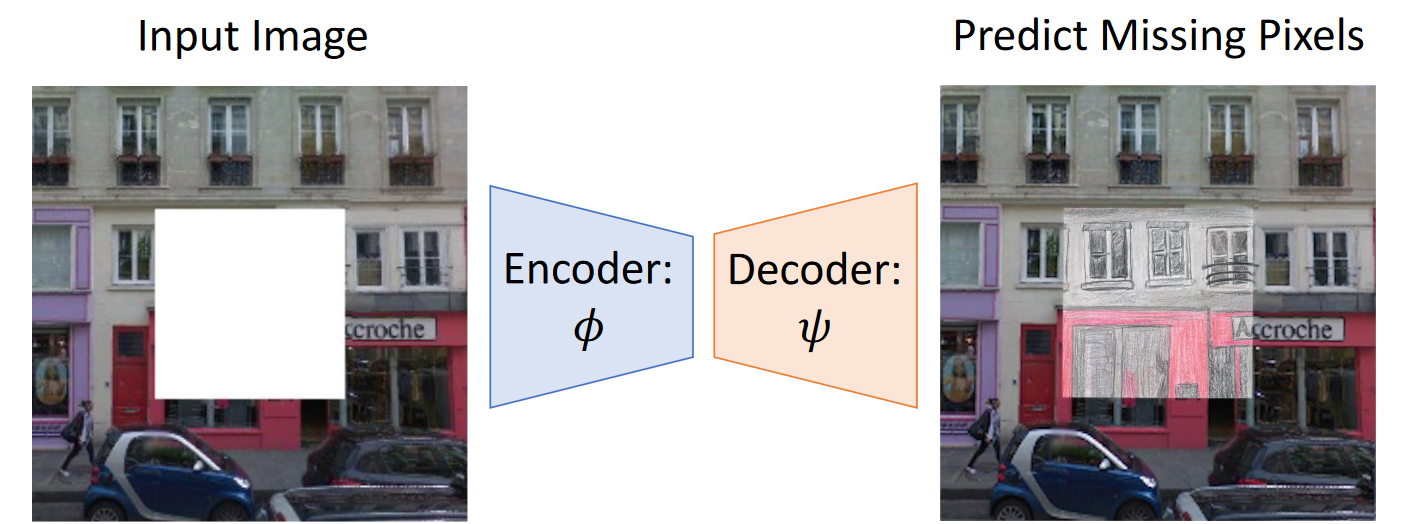
What is inpainting?
You have missing pixels in an image and you paint them in. This is done with context learning I think, where, given a grid of image patches, determine their location to one another. Correspondingly, you might be able to determine an image patch, given another patch and it’s relative location. See the images below for detail.
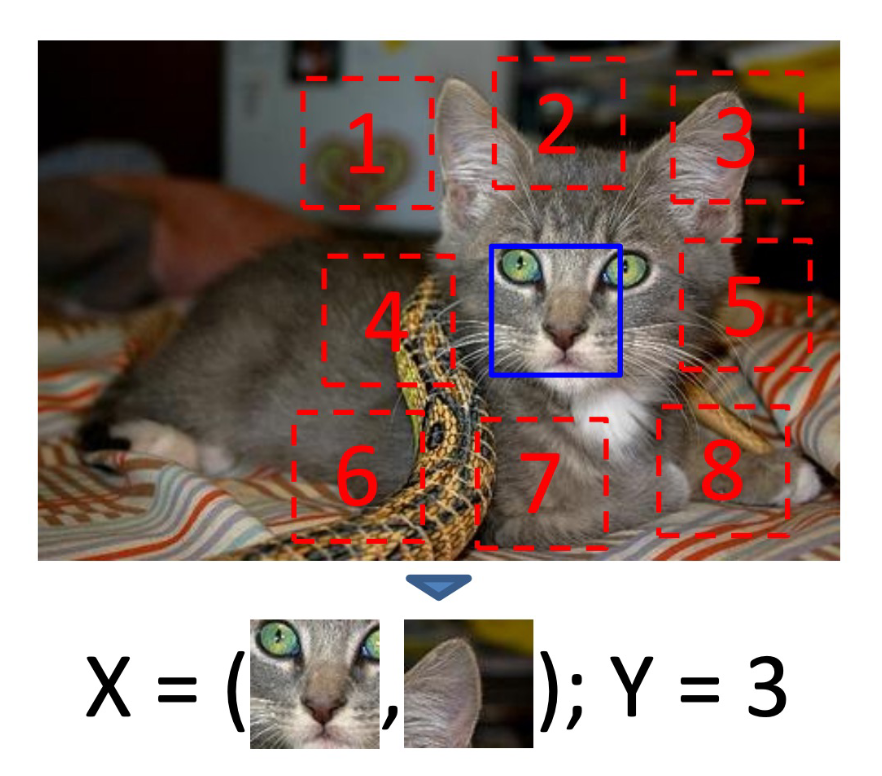
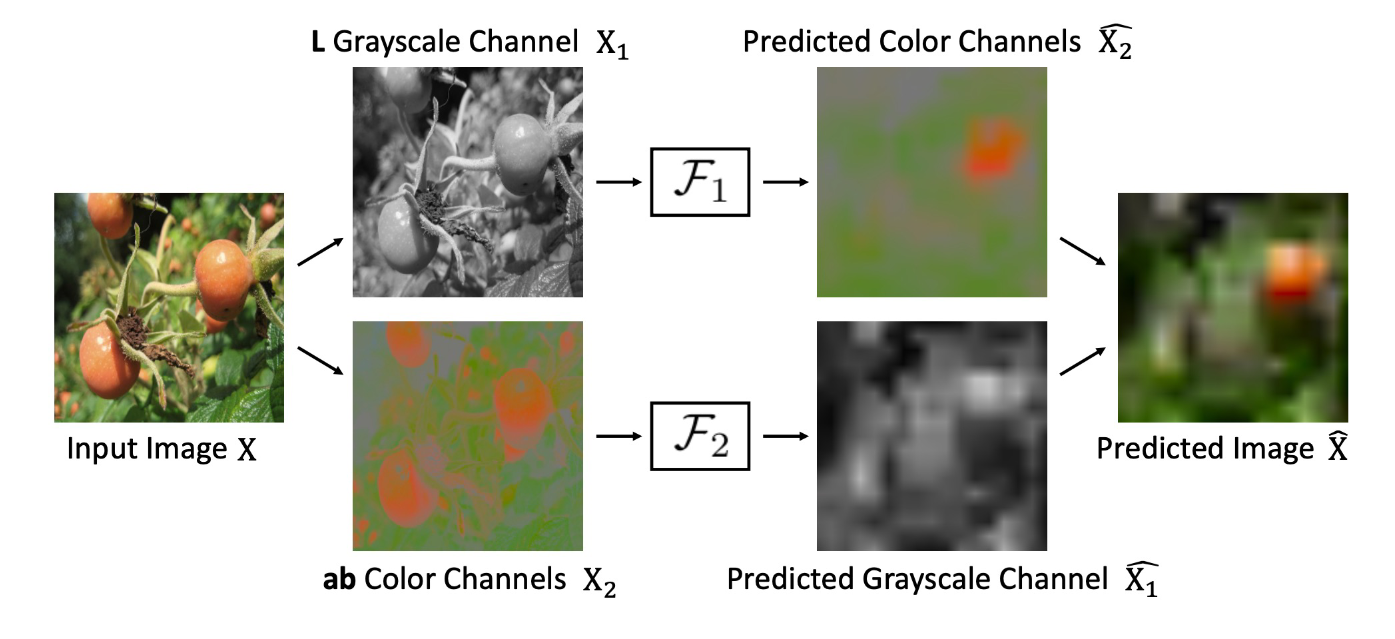
What is colorisation?
Turn grayscale into colored images.

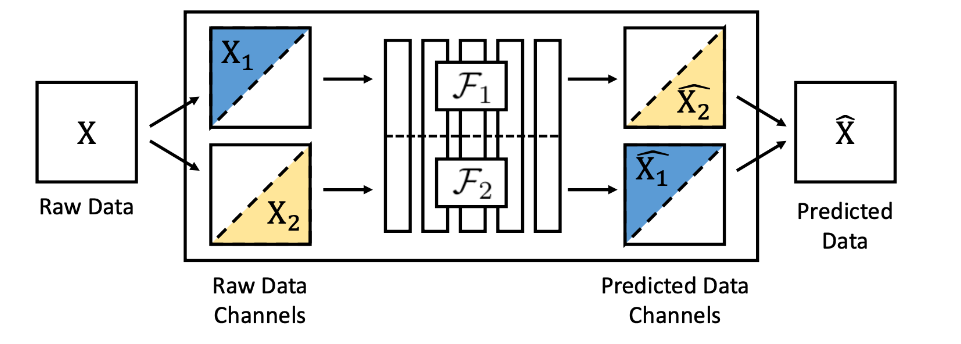
What are split brain autoencoders?
You have an input, you give half of it to one autoencoder, which is meant to predict the missing half, and you do the same with another half.
What is contrastive learning?
learn about what similar and dissimilar images are.
To do this, get a few images, say 3, then data augment each one so that there are a few slightly different copies.
Then make a similarity matrix between the images. So will be the similarity between image and . Naturally this matrix is symmetric.
Similarity is
Where is a (latent) feature vector of augmented image i.
Loss when training is like cross entropy, but the denominator doesn’t contain
If is a positive pair, is the temperature (?), is the number of augmentations and is the number of images.
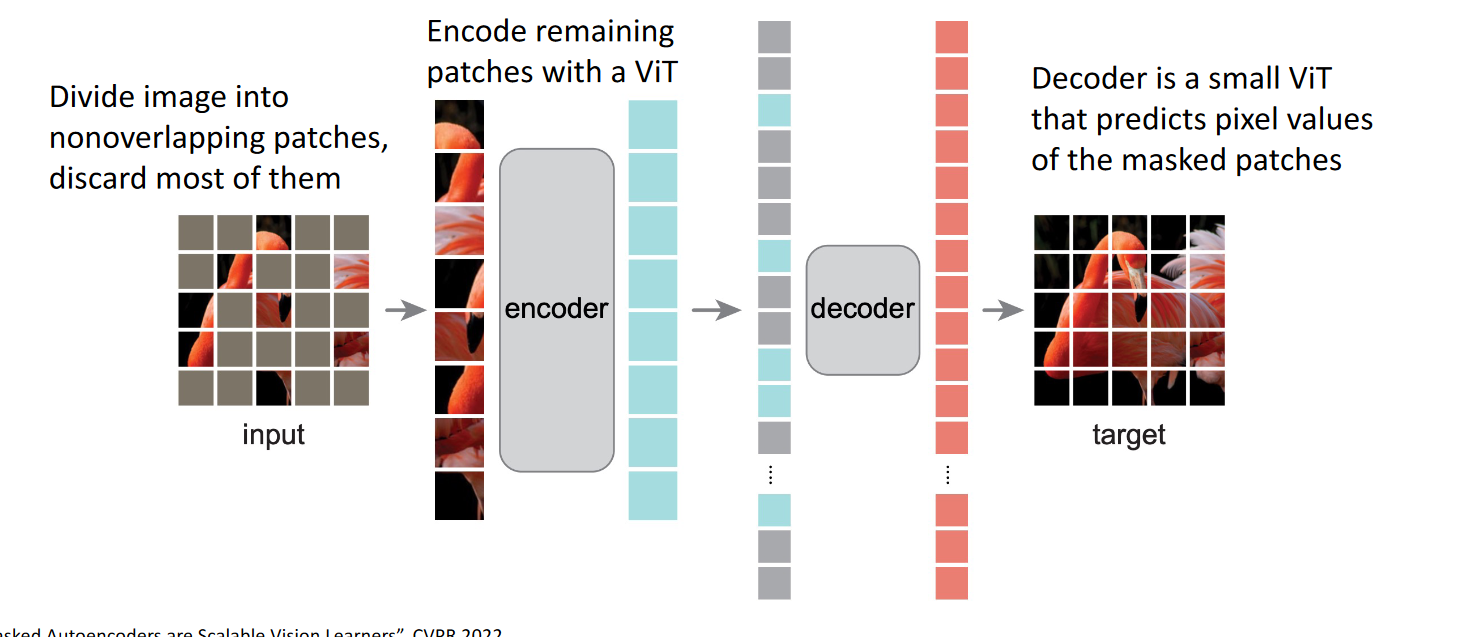
What are Masked Autoencoders (MAE)?
Basically, you have a masked image (masked by randomly opaque pixels), and you have to reconstruct it. You do that with an MAE.
Technially, you get the non-opaque pixels, run them through a transformer, then dom some stuff to it (NN stuff of some sort), run it through a decoder, reconstruct the image.

What is RedCap?
Reddit captioned datasets. 350 subreddits. 12M (image, caption) pairs.
Lecture 23 - 3D Vision
What is a major aim of 3D vision?
To model 2D images into 3D models, or to classify 3D models.
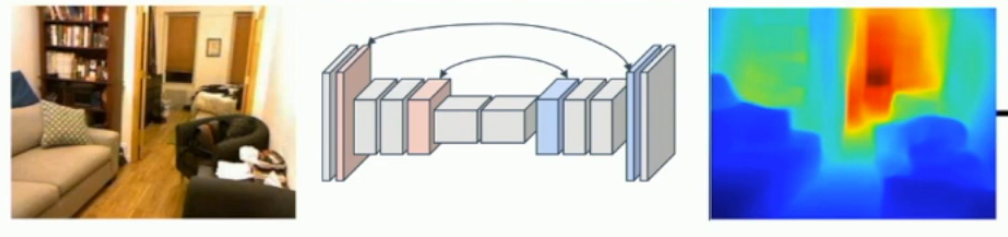
What is a depth map?
When you recieve an image you mask it with predicted depth per pixel.
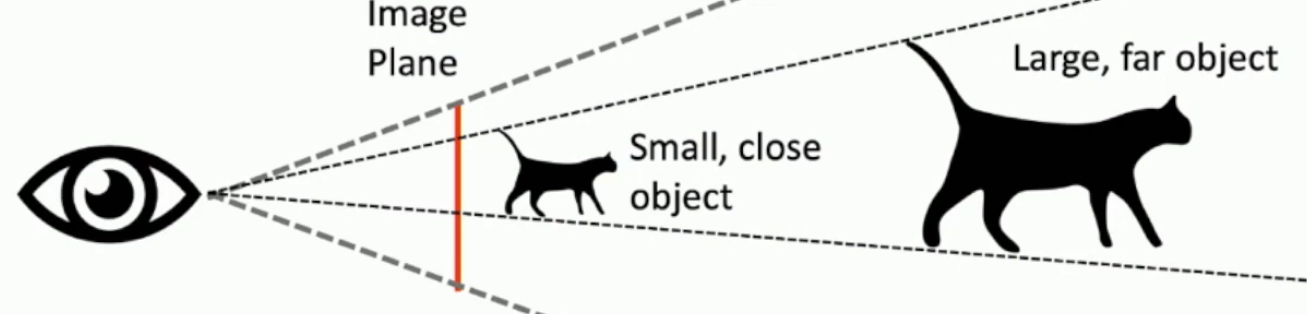
What is scale depth ambiguity?
If a cat is twice as big and 2 times as big then it’s hard to predict how far away it is since we have no depth perception from one 2D image.
What is the surface normal?
You predict a normal vector for each pixel, predicting which way it’s pointing.
In the below image, it looks like blue points up, green on one axis, and red on the other axis.

What are Voxel grids?
3D grids of cubes that predict the shape of an object; like minecraft.
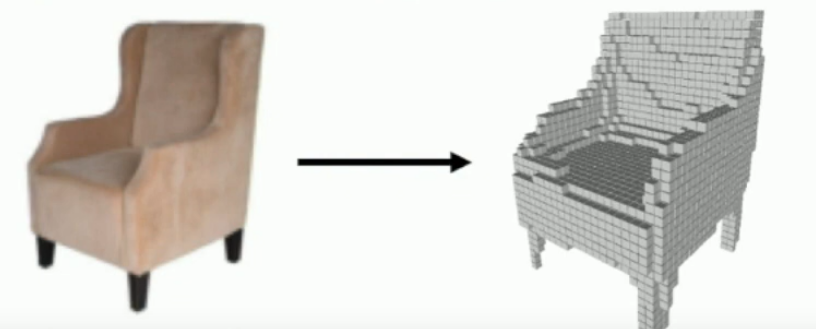
What is one pro and 2 cons of Voxel grids?
Pro
- Conceptually simple; just a 3D grid.
Cons
- Need a lot of boxes* to capture fine details
- Computationally intensive at higher dimensions
*High dimensional output.
How do you classify Voxel grid inputs?
3D convolution networks. So you have 3 dimensional activation maps, and an extra dimension for each filter.
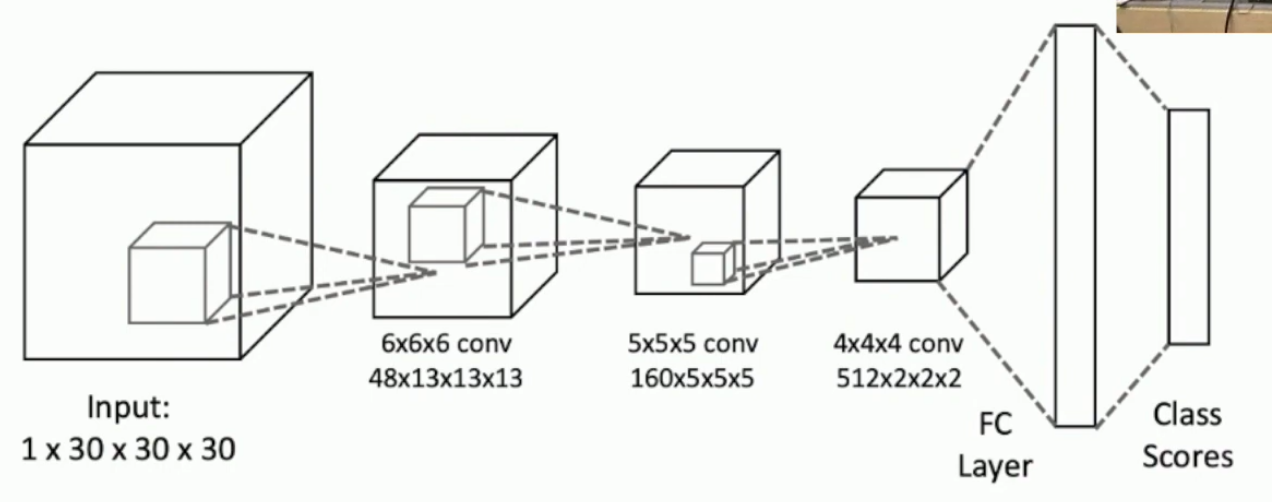
How do you convert a 2D image into a Voxel grid?
You can put the 2D image through a CNN to get a fully connected vector layer of latent variables, then you feed that vector into a 3D upsampling CNN. This is slow
What are Voxel tubes?
It’s a Voxel generating CNN but it’s a fully 2D convolutional network where the output has width and height V, and V activation maps, giving dim VxVxV, which is our voxel mapping.
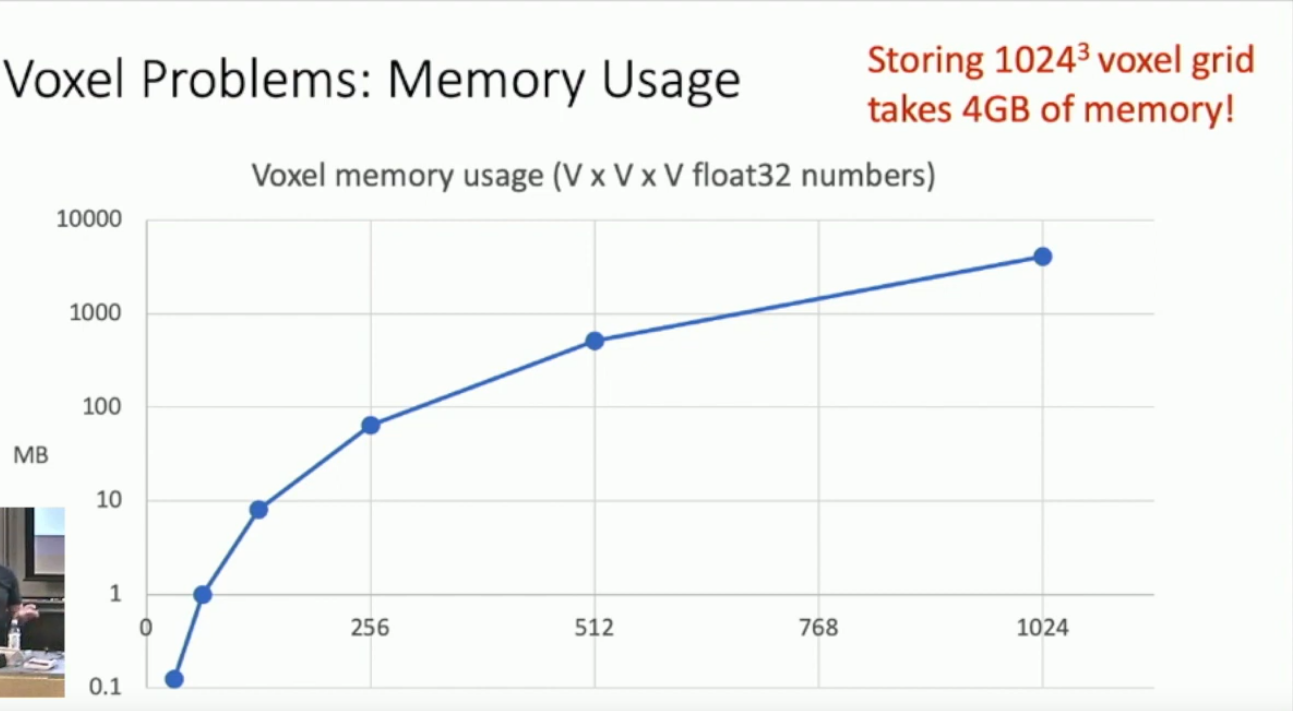
What is a dawback of Voxel grids?
They need a lot of outputs to model fine structures (Say 1024**3) and that becomes a memory issue.
What is are point clouds?
The model is approximated by points in 3D space, and we expand balls out of those points so the output looks like a cloud (of points).

What is a pro and a con of point cloud representations?
Pro
Smaller memory usage - can represent fine structures without huge numbers of points.
Con
The shape is bubbly, and not representative of what the actualy shape looks like. Like a rough sketch.
What is chamfer distance?
Sum of closest squared euclidean distances between 2 sets of points - so 2 sums.
Where are sets of points in , though could be in any dimension.
What is Triangle Mesh representation?
You have a set of points, you connect some and make triangles over the surface.
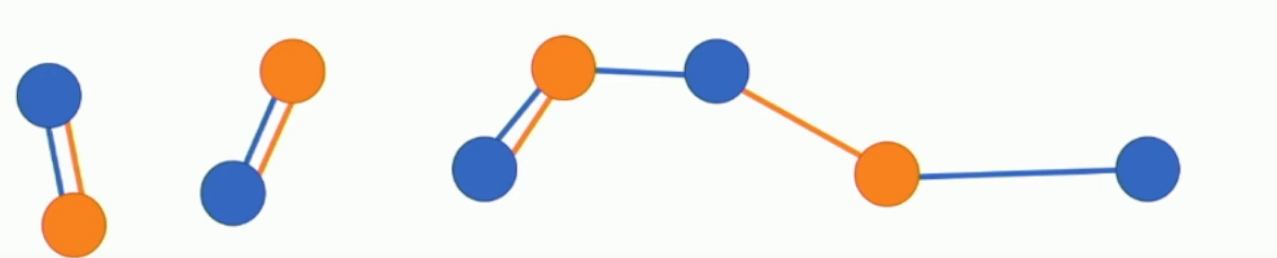
What is graph convolution?
You have a graph of vertices where each vertex is a vector, , at layer* . The output of a convolution operation is a sum over the set of adjacent vectors, , multiplied by the same matrix . The original vector is multiplied by a different matrix .
*Or timestep.
What is vertex-aligning of features?
Similar to RoI align in that it uses Bilinear interpolation, but I’m not sure what it actually is since it involves some (vague) projection of the 3D triangle mesh onto the 3D image feature vectors at some layer of the 2D CNN.
How do you get the Triangle-Mesh loss?
The problem is that you can represent the same shape with different meshes
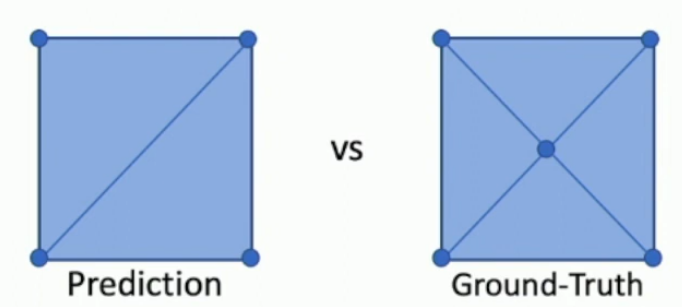
Convert meshes into point clouds by sampling points on the triangle planes and get chamfer distances.
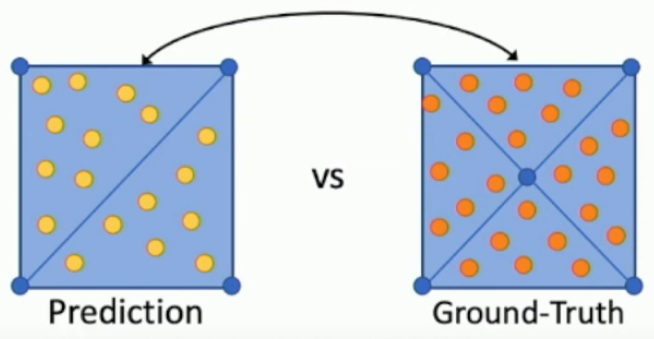
See Smith et al 2019, GEOMetrics for details on how to backprop through this.
What is the F1 score loss?
It’s like getting mAP. Every point in a point cloud has a radius, and if two radii intersect then you increase either precision or recall.
precision@t is the number of predicted points within some t of the ground truth points, divided by the total number of predictions.
recall@t is the number of ground truth points within some t of a predicted point, divided by the number of ground truth points
What are canonical vs view coordinates?
Canonical is where shapes are predicted in some 3D space, where the left leg of a chair will always be in some quadrant, right leg in another quadrant etc..
View coordinates predict coordinates based on where they are from the view of the camera.
What are 2 3D-shape datasets?
- ShapeNet - chairs, cars, airplanes, in synthetic/simulated environments
- Pix3D - real world images of IKEA furniture, IKEA has 3D meshes of all their products.
What is a Mesh R CNN?
Makes Meshes of objects detected with bounding boxes, from 2D input images. An additional head on top of a mask R CNN.
What is an issue with Mesh Deformation from a sphere? How is this addressed with Voxel+mesh?
You can’t make a doughnut out of a sphere, so it’s a topological problem. You can’t deform a sphere to have holes. And if your starting mesh has holes, then your final output mesh will have holes.
This is addressed with Voxel+Mesh by getting a low resolution voxel of the image, then having (a meshed version of that) as your input mesh, since voxels can have holes.
What regularisation loss is used alongside chamfer loss?
Smoothness of the mesh. Minimise euclidean distance between predicted points. However this doesn’t seem good for sudden changes, like edges of pillows on a couch, so regularisation should be far weaker than chamfer loss.
Why can’t we predict 3D dog models using voxel+mesh?
Because IKEA doesn’t sell dogs*.
*We don’t have (datasets of) 3D models of dogs.
Lecture 24 - Videos
What is the dimensionality of video input?
Where is the temporal dimension.
What is an issue with processing videos?
They’re huge. 1920x1080, 30fps, 1 minute video, for 3 bytes per input pixel, is 10GB.
This isn’t even taking into account intermediate convolutional layers, so it’s too much. We need to find an intelligent solution to this.
Essentially we :
- Reduce the resolution, to say 112x112.
- 16 timesteps, over 3.2 seconds, with 5fps.
Ends up being ~500kb, according to the slides.
What is a single-frame CNN?
Very naive, but surprising effective, version of a video model. Look at each frame and classify it with video labels, then take an average/mode (?).

What is a late fusion model? With and without pooling?
No pooling
Just like single frame, but in the end you concatenate, flatten and put through an MLP.
Pooling
Same but after you concatenate, you average pool to get Cx1x1x1, flatten that, and run that through an MLP.
What is an issue with late fusion?
It’s late (?) - Hard to compare low level changes between timesteps.
What is early fusion? How does this address an issue with late fusion?
You fuze them from the start and run it through a CNN to classify.
So you get and run that through a normal CNN.
What is an issue with early fusion?
Does not capture temporal order (?) No idea tbh.
What is a 3D CNN? (Slow fusion)
Basically, you run a 3D filter, of dim over activation maps of size
Over all activation maps.
Each layer is a 4D tensory .
What is temporal shift invarance?
In 2D conv, you get filters that go over all timesteps, this means that you need separate filters to detect movements at separate parts in the video; this is when the filters are not temporal shift invariant.
In 3D conv, you get filters of fixed timestep size less than the total #timesteps, which means each filter can detect a specific motion/change; these are temporal shift invariant filters.
What is a popular video dataset?
SPORTS-1M is a million videos annotated with the sport they’re of.
What is the C3D network?
It’s a network architecture; the VGG of 3D CNNs. Systematic. Takes 3x more gigaflops to run than VGG.
What is optical flow?
When you measure the vector difference between 2 images, to capture motion. Makes effective networks.
What is a two stream network?
You have 2 networks. One network has the video frames as input, the other network has the intermediate optical flow images, of which there are , since you have a vertical and horizontal input for each timestep difference.
How can we use RNNs in video classification?
You run sections of frames through a 3D CNN, probably 2-stream, and get some vector of latent outputs. Then connect the latent outputs along the timesteps as an RNN.
What is a Recurrent convolutional network?
Basically, a layered RNN where vectors are 3D cnns.
What is the structure of a spacial-temporal self attention layer for video? - Nonlocal Block
Key, Query and Value are found through 1x1x1 convolutions of the input tensor.
Get the Key-Query cross multiplication, feed it through a softmax to get attention weights. and then cross multiply that with the value tensor. This output is fed through another 1x1x1 convolutional layer. Then add that to a residual connection with the input.
What is a type of architecture for video classification that uses nonlocal blocks?
3D CNN → self-attention → 3D CNN → self-attention → 3D CNN
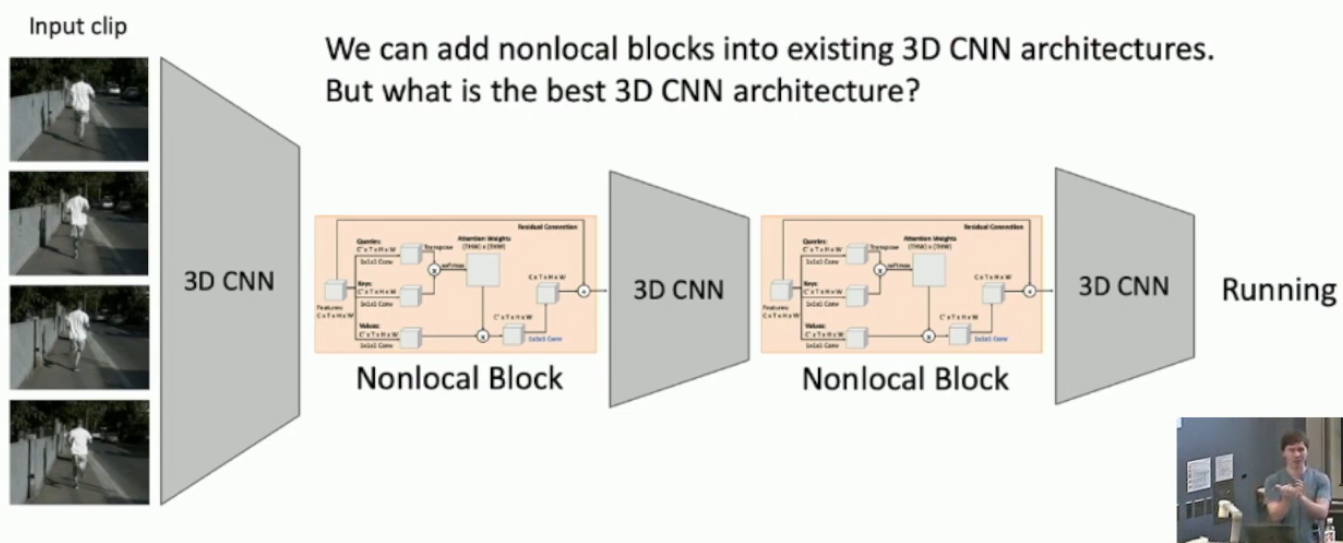
What is the notion of inflating a 2D architecture to 3D?
Just use old* 2D architectures and add on a third, temporal, dimension to each convolutional layer.
*Res-net for example
How can you transfer weights from a 2D architecture to 3D?
You just copy paste the spacial dimension over the temporal dimension; collate it.
How might you visualise a two stream network?
Same methods as in the visualisation lecture. For example choose an activation you like, and do gradient ascent on it for example. This simply follows from the visualisation lecture.
What are SlowFast networks?
Two stream network that with steams
- Short temporal dimension, large number of channels, large spacial. (Slow)
- Long temporal dimension, short number of channels, large spacial. (Fast)
Essentially you get a quick image of the whole scene with the fast stream, and get a detailed image of a fragmented version to the whole scene.
Works well.
What is temporal action Localisation?
Where you look over all timesteps and essentially put bounding boxes over differnt sections that have different classifications - seems easy with the single-frame CNN.

What is an example spacial-temporal-action-localised dataset?
AVA dataset.
They looked at a bunch of movies and analysed what everyone was doing.

Lecture 25 - Conclusion
Good summary.
Additional Lecture - Lecture 21 from 2019 - Reinforcement Learning
What are 3 examples of reinforcement learning?
- Chess
- Cartpole
- Atari Games
What is a Markov decision process (MDP)?
So something is a Markov process when the next guess does not depend on previous states.
What is the optimal policy ?
The policy that maximises expected reward.
What is the value function?
A value function gives the expected reward from following a policy, , from a (initial) state .
What is the Q function?
Like a value function, but it’s gives the expected reward given a policy, and starting at state and doing action .
What is the optimal Q function?
The Q function of the optimal policy.
How does the optimal Q function relate to optimal policy?
The optimal policy gets the actions that maximises reward in the Q function.
What is the Bellman equation?
Where after action we get reward and end up in state .
What is the significance of a Q function that satisfies the Bellman equation?
It is the optimal Q function.
Where do neural networks enter reinforcement learning?
We use them to approximate the Q function.
What is Deep Q learning?
Using a deep neural network to approximate the Q function.
Extra
What is GBC?
Goodfellow, Bengio, Courville - Deep Learning Book
Why use Colab?
- GPU memory is 15GB. My GPU has 3GB and it crashed a few times…
- They have A100s, which probably take stupid compute, but they are FAST.
Interesting Papers
- Xie et al, 2019 “Exploring randomly wired neural networks for image recognition”
- Papers on training hyperparameters.
- CNN features off the shelf: an astounding baseline for recognition.
- for training on lot of GPUs Accurate Large minibatch SGD (Goyal et. al. 2017)
- “Highway Networks” Srivastava et al 2015
CNN Architectures II
- Shufflenet 2018 Zhang et al
- Zoph and Le, “Neural Architecture Search with Reinforcement Learning”
- Brock et al, “Characterizing Signal Propagation to Close the Performance Gap in Unnormalized ResNets”, ICLR 2021
- Brock et al, “High-Performance Large-Scale Image Recognition without Normalization”, ICML 2021
- Bello et al, “Revisiting ResNets: Improved Training and Scaling Strategies”, NeurIPS 2021
- Tesla AI Day 2021, https://www.youtube.com /watch?v=j0z4FweCy4M
- Hu et al, “Squeeze-and-Excitation networks”, CVPR 2018